OER Computational Publishing Packages for Teaching Open GLAM

An experimental computational publishing teaching unit used with students of the Open Knowledge class at the Hannover University of Applied Sciences and Arts in partnership with the Open Science Lab, TIB.
During the summer semester, the students of the Data Science major in the Information Management study programme at Hannover University of Applied Sciences and Arts were to deal with topics within Open Knowledge in a practical way. Thanks to the newly established Joint Lab between TIB and HsH, projects at TIB (here in the Open Science Lab within the project NFDI4Culture, Task Area 4: Data publication and data availability) can be integrated into teaching even more easily than before and students can thus be taught very application-oriented knowledge.
Eleven students completed the class unit which was carried out over March to April 2023. An open access OER guide to running the class, a template publication for use in the class are online on GitHub and designed for OER reuse. Full class information and resources are on Wikiversity – ‘Modul “BIM-224, SoSe 2023, Blümel” im Kompetenzfeld Data Science des Studiengangs Informationsmanagement an der Hochschule Hannover’.
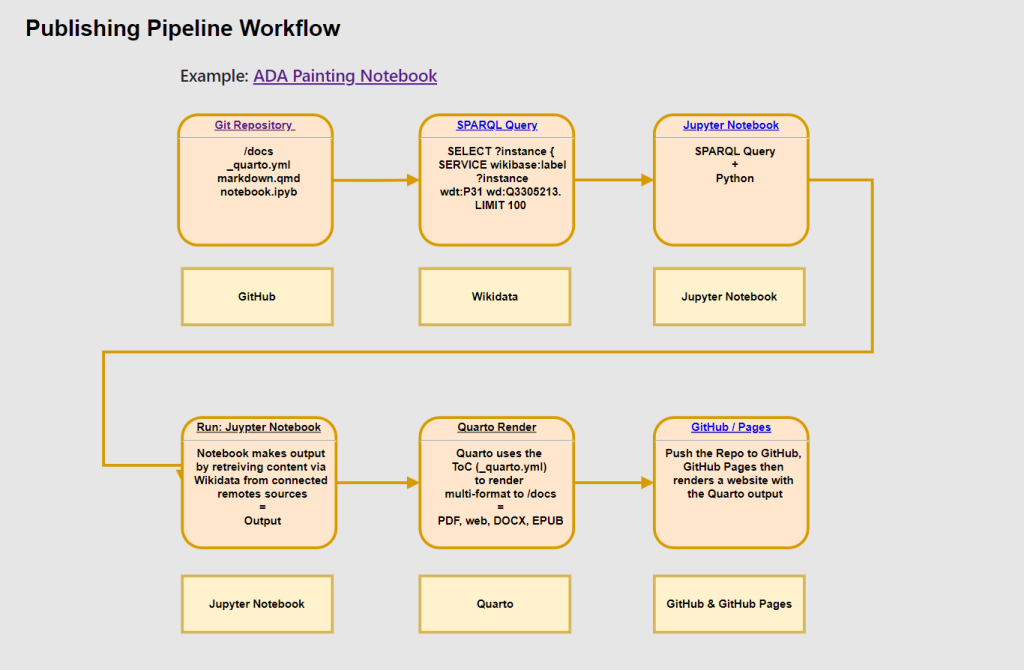
The prototype publication exercise uses the ‘ADA Semantic Publishing Pipeline’ and involves creating a fictional ‘exhibition catalogue’ drawing on a Wikidata based cataloguing of seventeenth century paintings deposited by the Bavarian State Painting Collections.
The software used is a publishing pipeline that authors can script and utilises Jupyter Notebooks to retrieve content from linked open data sources – Wikidata and Wikibase, and more – to produce multi-format outputs, such as: PDF, web, ebook, docx, etc.
The goal of the project is to add a publishing layer, supporting open access reuse, to digital cultural collections that are catalogued using Wikidata or Wikibase with linked open data (LOD).
Key open source software used in the pipeline includes: Jupyter Notebooks, Quarto, Wikibase, and GitLab. The pipeline model allows for the modular connection of new software and other pipelines.
Examples of student’s publications
Each of the students personalised their publication – selecting different cultural collections from Wikidata, styling the publication, and adding bibliographic data for their publications and minting DOIs on Zenodo:
- Ahmad Hasan Ahmad – https://ahmad19111.github.io/catalogue-003/
- Ahmad Aroud – https://ahmadaroud.github.io/catalogue-003/
- Jana Lisa Cornelius – https://janacnl.github.io/catalogue-003/
- Fynn/Anna Rahr – https://calnfynn.github.io/catalogue-003/
- Memo Loran Tuku – https://mloran.github.io/catalogue-003/
The publications were made up of: cover, colophon, essay, and collection entries. The collections are made of catalogue entries and images.
The learning points covered are extensive and include the foundations of Git, Wikidata, Jupyter Notebooks, and multi-format rendering with Quarto/Pandoc. Although this is a lot to get through – it has the benefit of giving participants hands-on experience with the core tools, competencies, and skills needed for working with computational publishing.
The tasks include: real-time collaborative editing; creating a Wikidata query of a collection; displaying a painting catalogue sample collection from a Wikidata LOD query for a multi-format publication; editing a Jupyter Notebook in MyBinder; embedding media objects: video – TIB AV Portal, and 3D – Semantic Kompakkt; using GitHub; accessing API content for colophon creation from Thoth.pub; editing Wikidata collection query in Juypter Notebooks; asynchronous collective working and making a publication from multiple remote Linked Open Data (LOD) sources, and; rendering a multi-format publication with CSS styling.
ADA: OER Reuse Package
- Class Guide: Publishing from Collections Using Linked Open Data (Updated version from FORCE11 Scholarly Communications Institute [FSCI] Version – Summer 2023)
- GitHub repositories with Jupyter Notebooks used:
A small library of Jupyter Notebooks has been made which use SPARQL queries and Python code to fetch LOD from a variety of sources including: painting data from Wikidata and Wikibase, book metadata from Thoth, 3D models from Semantic Kompakkt, videos from TIB AV Portal, ORCID, and from IPCC Reports via #semanticClimate.
- ADA HsH Template – Baroque Painting
- ADA – Benchmark Notebook – For testing purposes
- ADA Painting Notebook – Use case #1 Exhibition Catalogue
- ADA Book Catalogue Notebook – Use case #2 Publishers Catalogue
- City Climate Plans Notebook – Use case #3 Climate Reader
The class unit was coordinated by Simon Worthington NFDI4Culture @Open Science Lab, TIB, Hannover and Professor Dr Ina Blumel (Open Knowledge course leader HsH) — HsH, NFDI4Culture @Open Science Lab, TIB, Hannover. With development work and support from Simon Bowie of COPIM.
Prototype series and software pipeline has been developed as a collaboration between the NFDI4Culture – Consortium for Research Data on Material and Immaterial Cultural Heritage, at the Open Science Lab, TIB; with, COPIM (Community-led Open Publication Infrastructures for Monographs) and the partner publisher Open Book Publishers.
Note
Following on from the use of the ADA Semantic Publishing Pipeline as a unit in the course, Lozana Rossenova of the Wikibase4Research service from the Open Science Lab took over the class with an additional teaching unit and added data science and data visualisation components to the publications.
Bibliography
Open-Access-Tage 2023. Poster: Worthington, Simon, and Blümel; Ina. Baroque AI. Zenodo, June 19, 2023. https://doi.org/10.5281/zenodo.8376274.
COPIM Experimental Publishing Outputs (WP6: Experimental Publishing and Reuse) – https://copim.pubpub.org/work-package-6 | About WP6: https://www.copim.ac.uk/workpackage/wp6/
Bowie, S. (2023). A new model for computational book publishing. COPIM. https://copim.pubpub.org/pub/computational-book-model

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.