AI Open Climate Reader: Connecting IPCC Reports to Climate Change Plans
‘AI Open Climate Reader’ is search that collects all your sources in a neat publication package you can share — that’s the ‘Reader’ — it can be peer reviewed, is transparent, and reproducible.
AI Open Climate Reader is a proof of concept software prototype that can query scientific corpora and create ‘reader’ publications using self-hosted AI with added human review. The types of ‚reader’ publications it would make are: Referenced summaries, suggestions for literature, and guides on specific topics. The publications would have all the references collated as full text in the publication.
The problem that the prototype is looking to solve is the inaccessibility of climate science research by those outside of academia. Example problems are the use of PDFs that prevent searching and reuse — try using Google to search for IPCC reports for ‘city climate plans’ — you can only enter the top level of very large documents which effectively leave the reader lost. Another example problem is just the quantity of literature to wade through, sites like EuropePMC make papers accessible as open access full text, but still there are too many to efficiently sort. And lastly, even if you do find what you’re looking for chances are it will be written for academics and not for other professionals or the wider public.
The solution to these problems is twofold; firstly, the semanticClimate software py4ami semantifies a corpus — this means it breaks down the literature into the smallest units possible such as sentences — and makes them machine readable, tagging these parts with linked open data ontologies; secondly, using self-hosted AI can generate easy-to-read summaries, literature suggestions, and even whole guides. All of this is done with open source software, is self-hosted, and digital sovereign.
The proposed prototype is at a proof of concept stage and the semanticClimate open research project is looking for volunteers, support, and resources to make this prototype and further rounds of development. A ‘mock-up’ prototype was made at the FORCE11 Scholarly Communications Institute (FSCI) summer school hackathon in August 2023. See: IPCC Reports and City Climate Change Plans. The next development round will kick off at the Open Science Barcamp in Berlin, September 21st 2023.
The ‘mock-up’ prototype had the use case of city climate change plan authors, which we continue to base our use case around for this new AI round of prototyping. As climate change events quickly unfold cities need to be more agile and react quickly. Being informed on climate adaptation measures from the global community becomes critically important, especially as uncommon weather events start appearing in a locale not prepared for them, but that are normal for another region. As an example, Madrid in Spain, only used its national warning system for the first time in September 2023 for flood warning, calling and SMSing all phones, whereas in the USA the system use is a regular part of daily life. If a city official can learn about the latest findings and reports on implementing new systems then they can make better informed decisions.
Our use case is for climate plan authors who need to find IPCC Report recommendations, sections, visualisations, and external references and use these in their own city climate plans as well as to distribute the content to their community for the purpose of making the plans democratically — understandable, accountable, and transparent.
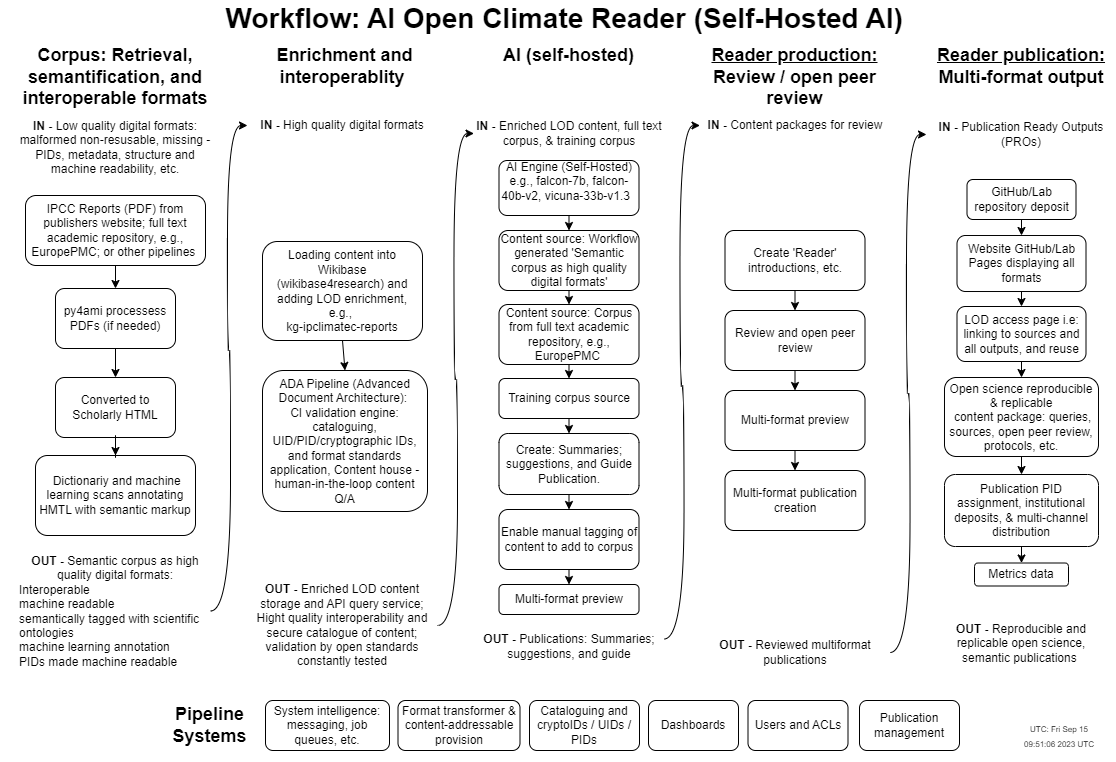
The proof of concept prototype will bring together a number of existing components and run test scenarios using real literature. Firstly there is corpus retrieval and semantification, this is done with the py4ami text data mining and machine learning suite, which would deposit content in a Wikibase instance as with the AR6 IPCC Report which was experimented with in an earlier hackathon, with new Wikibase instances managed by the Wikibase4Research service. Then self-hosted AI would be used to create the publications — example AI models are falcon-7b, falcon-40b-v2, and vicuna-33b-v1.3. Review and multi-format publishing is then run to create a reproducible and replicable, semantic publication on GitHub/Lab Pages using the ADA Semantic Publishing Pipeline which harnesses Fidus Writer and its Open Journals System JATS plugin for review. Not only can the content be used by others, but also the queries used to make the initial corpus and the AI publication queries can all be reused or built on.
semanticClimate is an open research project run by volunteers. Thank you to all the team and especially Summer 2023 Interns and staff from the ICAR-National Bureau of Plant Genetic, India, who contributed to the ‘mock-up’ prototype. Thanks to Simon Bowie of the COPIM project and Centre for Postdigital Cultures – Coventry University, UK for the HTML to Markdown converter. Thanks to Johannes Wilm of Fidus Writer for his AI recommendations and AI scoping. Lastly, thank you to Lozana Rossenova for being at the helm of Wikibase and support from Wikibase4Research services. ADA Semantic Publishing Pipeline from the NextGenBooks service and Wikibase4Research service are provided by the Open Science Lab, TIB and supported by NFDI4Culture research as part of the National Research Data Infrastructure Germany (NFDI).
Note
This blogpost is the second part of a pair of posts. See the first prototype blogpost in the series Ami Meets Ada: Connecting IPCC Reports with City Climate Change Plans.

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.