Language Discourse in the context of Natural Language Processing – A Quick Look
Natural Language Processing or NLP is a field of artificial intelligence that gives the machines the ability to read, understand and derive meaning from human languages. Discourse processing, as a subfield of NLP, is a suite of NLP tasks to uncover linguistic structures from texts at several levels, which can support many downstream automated text mining applications.
Discourse takes various modalities, structures, and mediums. Among the commonly experienced mediums are face-to-face chats, telephone conversations, television news broadcasts, radio news, talk shows, lectures, books, and scientific articles of which the latter form is of particular interest at TIB handled within its next-generation scholarly communication digitalization efforts via the Open Research Knowledge Graph. Intriguingly, each of these forms of discourse follow a logical structural nuance depending on the medium. The advancement of the digital age including social media communication has further led to expansion of logical discourse structures. These include blog-posts, emails, websites, review sites of products, hotels, restaurants or movies, and, finally, social media streams such as Twitter, Facebook, Reddit, #slack channels, Q&A portals such as Quora or Stack Overflow, etc., with a growing list as new mediums of communication over the World Wide Web are invented.
Broadly, Discourse is categorized as either written or speech. It is also categorized as either monologue or conversational which include dialogues. In this context, Discourse Processing then involves identifying the topic structure, the coherence structure, the coreference structure, and the conversation structure — the latter specific to conversational discourse. Taken together, these structures form the nuts and bolts of specific NLP applications such as text summarization, essay scoring, sentiment analysis, machine translation, information extraction, and question answering.
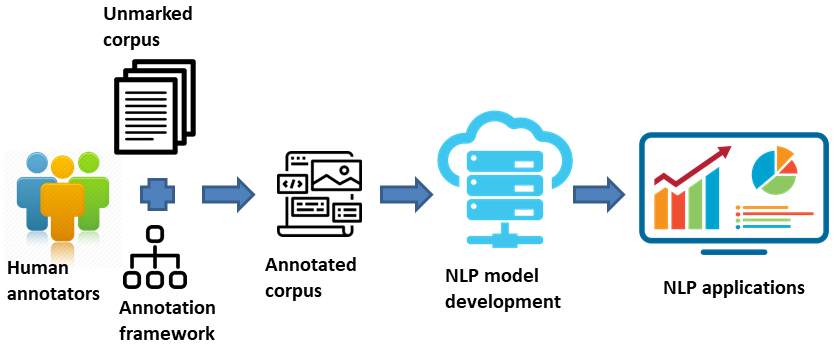
On the one hand, human readers can implicitly process various linguistic phenomena to comprehend communication; on the other hand, machines need these linguistic phenomena explicitly represented via an annotation framework or methodology applied to text or speech. The Figure below depicts a simple NLP model development lifecycle. Of keen interest then in the Figure is the annotation framework applied to unmarked corpora to produce an annotated corpus to train machine learning applications.
In the context of Discourse Processing, Linguists have proposed various theories of Discourse structures which are indeed realized as the annotation framework of natural language toward their machine interpretability for NLP tasks. The prominent ones are Segmented Discourse Representation Theory [1], Discourse Lexicalized Tree Adjoining Grammar [2] which was the model adopted to annotate discourse relations in the Penn Discourse Treebank Corpus comprising over 1 million news articles from the Wall Street Journal, and, last but not the least, Rhetorical Structure Theory [3].

Discourse annotation frameworks generally establish logical relational structures between clauses and sentences of language generally triggered by some phrase. Table 1 shows the Time and Causal discourse relations, as examples, in three sentences triggered by „since“. Other relations are: Consequence triggered by „so“, „as a result“, „consequently“, „thus“; Comparison and contrast triggered by „just as“, „similarly“, „in contrast“, „unlike“; Summative triggered by „To conclude“, „all things considered“ and more…
We now get to the more interesting part, i.e. the downstream applications perspective. Let’s take one example. Automated Essay Scoring — a trending research area given the plethora of e-learning opportunities out there today. Statistical models for automated essay scoring rely on their learned repetitions of discourse relations in an annotated corpus of well-written text to score new essays as high or low on logical coherence as one evaluation factor.
Finally, bringing into focus a more niche application area — that of building Scholarly Knowledge Graphs over the scholarly communication in scientific papers. It is not uncommon to find knowledge graphs in biomedicine that rely on causality patterns in the discourse of scientific papers to automatically extract knowledge between treatments and diseases. Recently, we conducted and published a preliminary study in the Journal of Data and Information Science titled „Sentence, Phrase, and Triple Annotations to Build a Knowledge Graph of Natural Language Processing Contributions—A Trial Dataset„. It would be interesting to see additional layers of discourse pattern annotations over our data to realize advanced inference NLP tasks.
Now over to you! In this post, I have barely managed to scratch the surface of language discourse processing for NLP tasks. Indeed an enormous field of research with various perspectives quite formidable to be a sole endeavor. Thus, to gather as many perspectives on the theme, we make a call for submissions of research to a Special Issue (SI) on „Information Extraction and Language Discourse Processing“ for Journal Information (ISSN 2078-2489). Your submissions will be published on a rolling basis until the close of the SI on December 10th, 2022. More information on the SI and the submission process can be accessed here.
References
- Asher, Nicholas, Nicholas Michael Asher, and Alex Lascarides. „Logics of conversation“. Cambridge University Press, 2003.
- Webber, B. (2004). „D‐LTAG: extending lexicalized TAG to discourse“. Cognitive Science, 28(5), 751-779.
- Mann, W. C., & Thompson, S. A. (1988). „Rhetorical structure theory: Toward a functional theory of text organization“. Text-interdisciplinary Journal for the Study of Discourse, 8(3), 243-281.