Vor der Archivierung: Kontrolle der Vollständigkeit bei Wiley DEAL Journals
Große Mengen an e-Journals erfordern eine automatisierte Kontrolle ihrer Vollständigkeit. Die Langzeitarchivierung entwickelt praxisorientierte Lösungen.
Der DEAL-Vertrag mit dem Publisher Wiley funktioniert in zwei Richtungen. Er berechtigt die teilnehmenden Einrichtungen sowohl zum Open Acces Publizieren als auch zum lesenden Zugriff auf das e-Journal-Portfolio. Um gerade Letzteres dauerhaft gewährleisten zu können, ist die Langzeitarchivierung ein wesentlicher Bestandteil des Vertrages.
Die TIB fungiert hier als „Dark Archive Responsible Entity“. Der Publisher liefert uns Materialien spezifisch für den Zweck der Archivierung. Im Falle eines Trigger-Events – zum Beispiel eines Ausfalls seiner Infrastruktur – darf der Inhalt aus dem Dark Archive ans Licht gebracht, das heißt, den anderen DEAL-Partnern zur Verfügung gestellt werden.
Size Matters
Die bisherige Datenlieferung von Wiley umfasst mehr als 2000 Zeitschriften ab dem Jahrgang 1997. Es sind über 5 Millionen Artikel, die mehr als 50 Millionen Dateien beinhalten. Da es im Kontext wissenschaftlicher Zeitschriften Sinn macht, betrachten wir einen Artikel als eine Archiveinheit (Intellectual Entity, IE). Ohne die Datenlieferung von Wiley beherbergt unser Langzeitarchivierungssystem bisher rund 150 000 IEs und knapp 2,5 Millionen Dateien. Diese Zahlen sind miteinander nur bedingt vergleichbar, denn die dahinterstehenden Inhalte sind heterogen. Zum Beispiel sehen die Datenstrukturen von IWF-Filmen völlig anders aus als die von Zeitschriftenartikeln. Dennoch lassen die Größenordnungen erahnen, dass die Verarbeitung solcher Datenmengen neue Werkzeuge und Arbeitsweisen erfordert.
Vor der Archivierung
Mit der Entgegennahme der Daten sind diese noch längst nicht archiviert. Sie müssen in das Langzeitarchivierungssystem eingespielt werden, wofür wir mit dem sogenannten CSV-Deposit bereits einen Workflow etabliert haben, der die automatische Verarbeitung großer Mengen von Archivpaketen ermöglicht (die Metadaten werden per CSV-Datei übergeben, daher der Name).
Das Archivierungssystem führt seinerseits Valididäts- und Qualitätsüberprüfungen der übergebenen Daten durch. Eine Frage kann es allerdings nicht beantworten: Sind die Daten vollständig? – Die Kontrolle, ob die gelieferten Daten tatsächlich dem entsprechen, was angekündigt wurde, erfolgt daher vor dem Ingest, im Rahmen der Pre-Ingest-Workflows.
Ist auch alles da?
Die Überprüfung von großen Datenmengen ist immer an die Bedingung geknüpft, dass die Strukturen möglichst homogen sind. Bei Zeitschriften stehen die Chancen dafür gut. Es gibt etablierte Hierarchie-Elemente, wie z. B. den Jahrgang, die Volume- oder Issue-Bezeichnung, die sich in den Metadaten niederschlagen. Zudem erhielten wir vorher Testlieferungen, aus denen die Struktur der Artikel-Ordner und der möglichen Inhalte (Anhänge und Ressourcen) ersichtlich wurde.
Die Homogenität der Daten ermöglicht überhaupt erst ihre automatisierte Überprüfung mit Python- oder Bash-Skripten. Wenn wir wissen, dass es für jeden Artikel einen Ordner gibt und sich darin genau eine XML-Datei mit den Metadaten befindet, dann können wir den Artikel zählen und wissen aus den Metadaten zu welchem Issue er gehört. Übertragen auf alle Artikel einer Zeitschrift erhalten wir so die Summen der Artikel pro Issue oder Volume.
Die ermittelten Summen allein sagen noch nichts über die Vollständigkeit aus. Die Datenlieferung von Wiley wird daher durch Inventory-Listen komplettiert. Wir haben ein Journal-Inventory, das uns zahlreiche Soll-Werte für jede gelieferte Zeitschrift vorgibt, sowie ein Issue-Inventory, dem wir die Namen der gelieferten Dateien und die Anzahl der Artikel pro Issue entnehmen.
Vollständigkeit als Vergleich
Für einen Abgleich müssen die tatsächlich gelieferten Daten mit den Informationen aus den Inventories verglichen werden. Dies scheint mit dem bisher Gesagten eine einfache Aufgabe zu sein. Neben der Anzahl der Artikel enthalten die Inventory-Listen jedoch weitere Datenpunkte, die für die Kontrolle unverzichtbar sind, deren Ermittlung aber komplizierter ist.
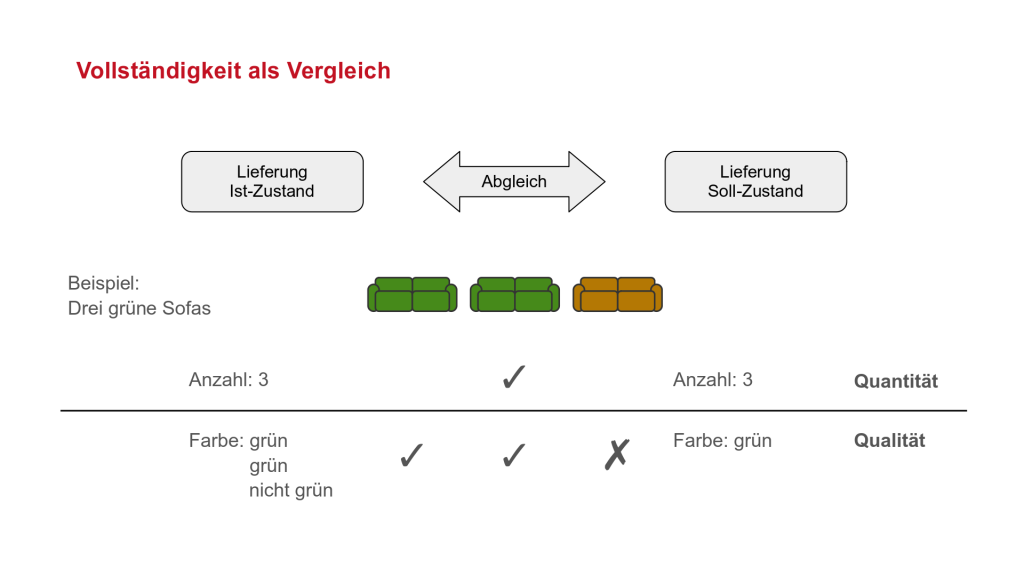
Ein anschauliches Beispiel: Jemand gibt eine Bestellung über drei grüne Sofas auf. Der Soll-Zustand der Möbellieferung ist damit bekannt. Tatsächlich geliefert werden zwei grüne Sofas und ein braunes Sofa. Bei der Kontrolle der Lieferung werden die Sofas gezählt – es sind drei, das entspricht dem Soll. Faktisch ist dies jedoch ein Fehler. Zwar wurden die Sofas quantitativ korrekt bestimmt, von ihren qualitativen Eigenschaften – der Farbe – wurde jedoch abgesehen. Damit zeigt sich, dass korrektes Zählen nur möglich ist, wenn die Objekte vorher auch qualitativ korrekt erkannt wurden.
Übertragen auf Zeitschriften: Wir brauchen eindeutige – in Skripte umsetzbare – Methoden um zu erkennen, dass ein Artikel ein Artikel ist, bevor wir ihn zählen können. Wiley liefert uns komplette Issues als ZIP-Archive. Diese enthalten jeweils einen Unterordner für jeden Artikel. Wir erwarten in jedem Artikel-Ordner eine XML-Datei mit Metadaten und in den meisten Fällen eine Repräsentation als PDF. Um die Artikel zu zählen, genügt es, die entsprechenden Ordner an der erwarteten Stelle in der Ordner-Hierarchie zu zählen. Für sich genommen ist dies kein zureichendes Kriterium, denn der Ordner könnte leer sein oder einen falschen Inhalt haben. Auch die zugehörigen XML-Dateien werden abgefragt, ausgewertet und gezählt – sollten also „unerlaubte“ Ordner auftauchen, die gar keinen oder falsche Artikel beinhalten, so sehen wir das an den Fehlermeldungen.
Die abzugleichenden Datenpunkte aus dem Inventory beschreiben den Umfang des gelieferten Teils einer Zeitschrift mit verschiedenen Parametern, die über einfache Summen hinaus gehen. So wird der Anfangspunkt der Lieferung beschrieben durch ein Datum, den ersten Volume und den ersten Issue. Das kann so etwas sein wie „1997“, „33“ und „4“ – die Lieferung beginnt im Jahrgang 1997 mit Volume 33 bei Heft 4. Analoge Angaben gibt es für den Endpunkt.
Für manche Artikel liegt nur eine Volltext-Repräsentation im XML-Format vor. Daher gibt es eine von der Artikelsumme abweichende Anzahl von Artikeln mit PDF-Repräsentation.
Wie zählt man eine PDF-Repräsentation?
Teilprobleme wie die Fragestellung, ob es sich bei einer vorgefundenen PDF-Datei um eine Artikel-Repräsentation handelt, behandeln wir mit pragmatisch am Material gewonnenen Heuristiken. Am Anfang genügen dafür Hypothesen auf Basis von Stichproben. Im Lauf der Verarbeitung der Daten zeigen sich in der Regel Schwächen, die dann iterativ in den angewandten Skripten nachgebessert werden.
Nehmen wir als Beispiel die PDF-Repräsentation eines Artikels. Der Artikel-Ordnern enthält mehrere Dateien:
APA13048
├── apa13048.pdf
├── apa13048.xml
└── image_n
├── apa13048-fig-0001.png
└── apa13048-toc-0001.png
Wir sehen eine PDF-Datei, eine XML-Datei und einen Unterordner „image_n“ mit zwei PNG-Grafiken. Auf Grundlage dieser Stichprobe können wir eine Regel formulieren, die mit der Position in der Ordner-Hierarchie operiert:
Annahme: Eine PDF-Datei im Article-Root ist die PDF-Repräsentation des Artikels.
Diese Annahme wird im Code umgesetzt. Wenn wir fehlerhafte Zahlen erhalten (der Abgleich scheitert), ermitteln wir die Ursache. Dank vorausschauender Programmierung haben wir detaillierte Fehlermeldungen, die uns zu einem anderen Artikel führen:
APA13084
├── apa13084_am.pdf
├── apa13084.pdf
├── apa13084.xml
└── image_n
├── apa13084-fig-0001.png
├── apa13084-fig-0002.png
├── apa13084-fig-0003.png
├── apa13084-fig-0004.png
└── apa13084-fig-0005.png
Hier sehen wir, dass unsere Annahme nicht korrekt war – im Article-Root befinden sich zwei PDF-Dateien. Unser Zählmechanismus zählt zwei Artikel mit PDF-Repräsentation, obwohl nur ein Artikel existiert.
Bei der Datei apa13084_am.pdf handelt es sich um eine Pre-Print-Fassung des Artikels („Author Manuscript“).
Die Annahme wird dementsprechend revidiert:
Neue Annahme: Eine PDF-Datei im Article-Root ist die PDF-Repräsentation des Artikels, wenn der Dateiname der XML-Datei entspricht.
In der Praxis hat sich auch dies als nicht zureichende Heuristik erwiesen. Über die skriptbasierte Auswertung einer 3000 Zufallsartikel umfassenden Stichprobe konnten wir jedoch zeigen, dass regelmäßige Korrelationen zwischen den Dateinamen von XML- und PDF-Repräsentation bestehen. Da es nur wenige Varianten gibt, konnte dies im Code berücksichtigt werden.
Ingest Material Provider
Unsere Lösung für das Problem des Datenabgleichs mit dem Inventory wurde in Python umgesetzt. Mit dem „Ingest Material Provider“ überprüfen wir jeweils eine Zeitschrift. Nur, was hier fehlerfrei durchgeht, wird weiterverarbeitet.

Userseitig wird die gewünschte ISSN eingegeben. Mit dieser Information ermittelt das Tool alle zugehörigen Issue-Ordner und verarbeitet alle dort enthaltenen Artikel. Die von Wiley vergebenen deskriptiven Ordnernamen werden dabei mit den vorgefundenen XML-Metadaten abgeglichen. Die auf Artikel-Ebene ermittelten Daten werden an die höheren Hierarchie-Ebenen Issue und Journal weitergereicht. Teilweise werden dabei die Zieldaten für den Abgleich erst aus den Daten der Artikel konstruiert.
Zum Beispiel erwarten wir, dass die Lieferung einer Zeitschrift mit „Issue 3“ endet. Ein Artikel kann die Eigenschaft haben, zu Issue 3 zu gehören. Ein Issue kann die Eigenschaft haben, Issue 3 zu sein. Aus beidem ergibt sich jedoch nicht, dass dies der Endpunkt der Lieferung ist. Diese Information wird erst sichtbar, wenn sie auf der Journal-Ebene im Kontext der gesamten Lieferung, aller Issues und ihrer Verknüpfung mit einem Datum betrachtet wird.
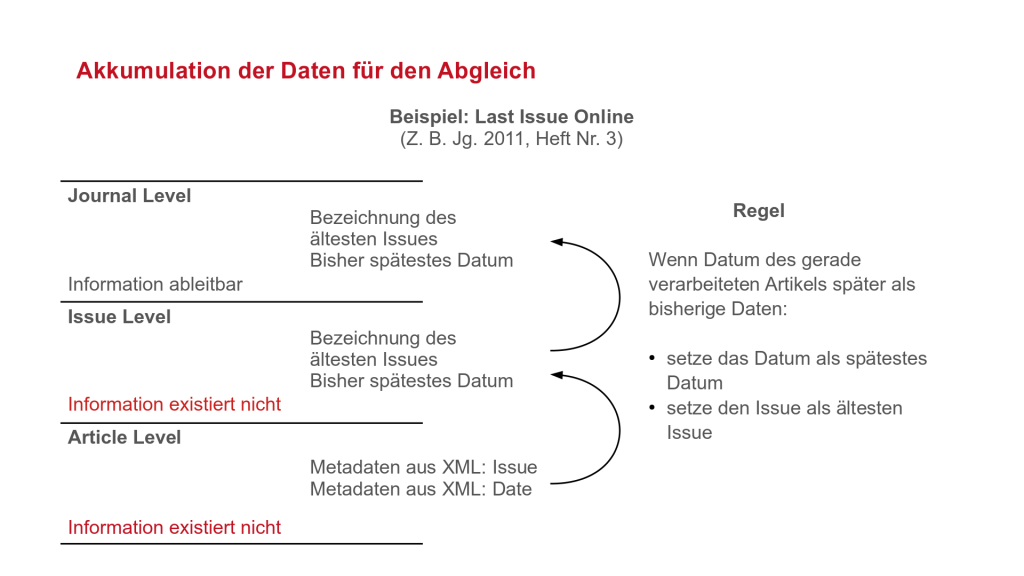
Wir bilden dies in Python mit Objekten ab – aus pragmatischen Gründe beschränken wir uns auf die Ebenen File, Article, Issue und Journal. Die abzugleichenden Datenpunkte definieren wir als Attribute. Für die Weitergabe der Daten innerhalb der Hierarchie implementieren wir die notwendigen Regeln als Methoden.
Nach der Verarbeitung aller Artikel sind auf der Journal-Ebene alle Daten akkumuliert, die für den Abgleich mit dem Journal-Inventory notwendig sind. Im Erfolgsfall wird die Zeitschrift für die Weiterverarbeitung – das Mapping der Metadaten, das Packen der Archivpakete und den CSV-Ingest – kopiert.
Fehlerfälle untersuchen wir manuell, da hier Entscheidungen notwendig sind, die wir nicht automatisieren können. Wenn ein Abgleich scheitert: Lag der Fehler in der Lieferung oder ergeben die Werte im Inventory keinen Sinn? Oder war es einfach ein Programmierfehler? Die zur Beurteilung notwendigen Indizien liefert oft nur ein Blick auf die tatsächlichen Daten.
Fazit
Einige hunderttausend Artikel aus der Lieferung von Wiley haben bereits ihren Weg in unser Langzeitarchivierungssystem gefunden. Das bedeutet, dass in vielen Fällen die Kontrolle der Vollständigkeit glückt – die gelieferten Daten stimmen mit den Inventories überein. Jenseits unserer Kontrolle – und das ist ein möglicher Mangel des Verfahrens – ist die Entstehung der Inventories. Wir vergleichen Daten von Wiley mit Daten von Wiley. Wenn bei der Zusammenstellung der Datenlieferung Fehler passiert sind, die dann genauso im Inventory verzeichnet wurden, können wir das nicht aufdecken.
Die tatsächlich aufgedeckten Fehlerfälle rechtfertigen den Aufwand. Wir fanden unter anderem falsch zugeordnete Artikel, falsch benannte Dateien, leere Dateien, die als Ressourcen verlinkt sind, irreguläre Abweichungen in den XML-Metadaten, aber auch Fehler in den Inventories bei offensichtlich korrekten Daten.
Ein Fazit, das wir bereits jetzt ziehen können: Ein Datenbestand dieser Größe verhält sich nie in seiner Gänze regulär. Automatisierte Ansätze der Bearbeitung können viel bewegen. Es bleibt aber immer ein Rest übrig, der sich allen bisher getroffenen Annahmen entzieht.

kümmert sich im Team Langzeitarchivierung um die Entwicklung von Skripten zur automatisierten Abholung von Open Access Journals
Hallo Herr Eisner,
vielen Dank für diesen spannenden Einblick in Ihre Mechanismen der Quantitäts- und Qualitätskontrolle.
Bei der Erstellung unserer Open Access Bibliographien IxTheo (https://ixtheo.de/), RelBib (https://relbib.de/) und KrimDok (https://krimdok.uni-tuebingen.de/), die wir im Rahmen der Fachinformationsdienste (FID) an der UB Tübingen verantworten, sind wir mit ähnlichen Problemen konfrontiert. Bei uns lautet die Frage, ob wirklich alle Hefte eines Jahrgangs und alle Artikel eines Heftes katalogisiert wurden oder ob es Lücken gibt. Und wenn, wo diese Lücken sind.
Relativ einfach zu prüfen ist, wenn ein ganzes Heft fehlt, da ja dann kein Metadatum (Artikel oder Rezension) mit einer entsprechenden Heftnummer vorhanden wäre.
Viel schwieriger ist es, Lücken innerhalb eines Heftes zu finden. Das ist das bei Ihnen erwähnte Problem mit den Inventories, die sie nicht kontrollieren können, da sie Ihnen vorgegeben sind.
Wir versuchen das über die Kontrolle der fortlaufenden Seitenzahlen abzufedern. Natürlich gibt es im regelmäßigen Fortgang von Seitenzahlen auch Gründe, warum ein Artikel nicht direkt an den vorhergehenden anschließt, z.B. weil eine Leerseite eingefügt ist oder Werbung geschaltet ist. Wenn aber der Abstand zwischen der letzten Seitenangabe eines Artikels und der ersten Seitenangabe des darauffolgenden Artikels zu groß ist, kann man vermuten, dass etwas ausgelassen wurde. Was der Grund dafür ist, müßte dann intellektuell geprüft werden.
Was man auf diese Weise natürlich nicht kontrollieren kann, wenn der letzte Artikel fehlen sollte …
Wieviele Artikel aber „normalerweise“ in einem Heft vorkommen sollten, könnte man über eine durchschnittliche Anzahl von Artikeln in einem Heft ermitteln. Viele Printzeitschriften hatten ja eine Begrenzung auf eine gewisse Seitenzahl und Vorgaben, wie lange ein Artikel sein sollte. Wenn man also als Durchschnittswert feststellt, dass bei Zeitschrift xy in der Regel immer 9-11 Artikel vorkommen, würde man bei einer gröberen Abweichung ebenfalls darauf aufmerksam, dass das „Inventory“ fehlerhaft sein könnte.
Lieber Herr Faßnacht,
vielen Dank für Ihren Beitrag! Das Thema Vollständigkeit wird uns sicher noch lange beschäftigen.
Ein Hoffnungsschimmer ist, dass die Problematik bei aktuellen digitalen Publikationen sich nicht in gleicher Weise stellt. Was wir in einer Publikationsplattform sehen können, ist in der Regel zugleich Ist- und Sollzustand. Bei Open-Access-Titeln können wir die Informationen einfach abrufen und auswerten, sofern dem keine technischen Hürden wie Anmeldeschranken entgegenstehen.
Wie Sie sehr treffend darstellen, verhält es sich bei digitalisierten Print-Publikationen anders. Eine wirkliche Garantie der Vollständigkeit könnte meiner Meinung nach nur gegeben werden, wenn ein Mensch Seite für Seite das Digitalisat mit der physischen Print-Fassung abgleicht – wobei er zugleich als mögliche Fehlerquelle (Ermüdung, etc.) wieder ins Spiel käme.
Auch wenn wir in Metadaten feine Unterscheidungen nach Typen wie „Article“, „Editorial“ oder „Commentary“ machen können: Bedrucktes Papier ist im wesentlichen Free-Form. Hinter so manchem „Article“ versteckt sich ein Call for Papers, eine Stellenanzeige oder gar ein Nachruf. Was gehört dazu, was nicht? Reicht es, nur die „Substanz“, also nur die Artikel zu scannen? Gehören Rezensionen von Software in einem Computer-Science-Journal aus den 80ern dazu? Ist nicht auch die ausgelassene Seite mit der Werbung Teil des Hefts? – Die Antworten auf diese Fragen sind arbiträr. Sie wurden bereits unterschiedlich beantwortet. Sicherlich auch oft mit guten Argumenten. Und das Resultat sind die heterogenen Datensätze, mit denen wir es nun zu tun haben.
Die Idee, weitere Indikatoren, wie die Seitenzahlen, zu überprüfen, finde ich gut. Das klappt natürlich nur so lange die fortlaufende Nummerierung der Seiten des Quarterly nicht durch die Sonderausgabe im Frühling durcheinandergebracht wird…