Examining Wikidata and Wikibase in the context of research data management applications
For several months now, our team at the Open Science Lab has been working with Wikibase to provide research data management services for the NFDI4Culture community. We have already shown its advantages when it comes to real world data with a specific use case for architectural and art historical data [1, 2]. At the monthly NFDI InfraTalk last week, there was an interesting question at the end of the session regarding the potential of Wikidata to be used as an application for science and research. We take this as an opportunity to expand the answer to this question with some more details about Wikidata, its potential applications, its relation to standalone Wikibase instances, and what Wikibase can offer in its own right.
A look at Wikidata’s past and present
Wikidata was released in 2012 and originally intended to help with very concrete issues in Wikipedia. It helped resolve redundancy and duplication across multi-lingual articles, and served as the source for infoboxes that are now ubiquitous across Wikipedia pages. Wikidata is distinct from its sister project, Wikipedia, for the fact that it stores structured data and makes that data accessible via a SPARQL endpoint. As of March 2022, it stores well over a billion statements and 97 million items on subjects across a vast range of knowledge domains. It highlights the power of a centralised and distributed approach [3] – a vast amount of information is accessible through a central endpoint in a standardised linked open data (LOD) format, all items have persistent identifiers (PIDs), and all that information is crowdsourced through collaborative editing efforts. Edits made by both human users and bots are tracked in a reliable version control system with clear provenance.
These qualities make Wikidata an attractive environment for data storage, curation and extraction. It is indeed already widely used across many domains of knowledge management, including scientometrics (e.g. WikiCite and Scholia initiatives) and – crucially – academic research data management. Communities of researchers in the life sciences [3], computer science and digital preservation [4], as well as cultural heritage [5], among other fields, have already documented their work and experience using Wikidata as research infrastructure. But they have also documented where the issues born out of dealing with a bottom-up ontology design and curation [6], the burden of vastness of scale on performance [7], the restriction of Wikidata being a secondary database (vs original research repository) [8], and ultimately trustworthiness [9], become problematic in the context of established scientific practice.
Despite all its disadvantages, the undeniable popularity of Wikidata – both as a repository to upload data to, and a rich resource on the LOD cloud to federate with – can also serve as a type of ‘Proof of Concept’ that its underlying software suite (Wikibase) can fulfil many of the core requirements of scientists and researchers dealing with structured data, while at the same time removing some of the issues born out of scale, policy, and governance particularities.
Wikibase as research data management (RDM) service
Thanks to many of the features already developed for Wikidata, Wikibase is already more than a single tool, it can instead be considered an umbrella of services [10], including:
- A graphical user interface (GUI) to a database with collaborative and version control features;
- A triplestore, editable down to the triple statement level (thanks to the requirements of Wikidata to serve as a verifiable source and secondary database, every triple statement can be edited and enriched with qualifying statements and references to external sources – all achievable via the GUI);
- A SPARQL endpoint with a GUI;
- An API for read/write programmatic access;
- A wide range of script libraries (PyWikibot, WikidataIntegrator), as well as additional user-friendly tools (QuickStatements, Cradle, OpenRefine reconciliation service), for data import/export.
Thus it can be argued that Wikibase is well suited to fulfil the need for end-to-end services to “LOD”-ify research data, while at the same time easing the learning curve to working with LOD compared to other existing knowledge graph tools.
Wikibase follows conventions for data structuring (and PID generation) set out by Wikidata (so all items receive a Q-number, whereas properties receive a P-number), however there is no requirement to follow Wikidata’s upper ontology [6], and Wikibase users can define their own ontologies from scratch. Here, the researchers deploying a Wikibase instance for their own datasets will be in complete control of how data is curated and described, while taking advantage of the familiar graphical user interface for data entry and editing. Furthermore, there is no need to deal with the “messiness” of collaborating with a vast and sometime anonymous international community (although, technically, non-logged-in edits are still tracked by IP address), which expands Wikidata’s vocabulary primarily in response to the needs of the Wikidata and Wikipedia projects.
Private Wikibase instances also rarely have to deal with performance issues born out of Wikidata’s scale, at least not until they grow into the magnitude of dealing with many millions of items. Importantly, private Wikibase instances can store original research data, as they don’t share Wikidata’s policy for being only a secondary database. In that sense, individual Wikibase instances can serve as primary sources for data to be later referenced in Wikidata (this type of decentralisation is in fact in alignment with the long-term strategy and vision behind Wikidata itself and the broader Wikimedia movement [11]). Private Wikibase instances can also hold various data licences, or remain entirely closed off from the open web, depending on the nature of the research and the need for privacy control (note that another restriction of Wikidata is the need for data to be licensed CC0).
Can too much freedom lead to more problems down the line?
The “open world” scenario of an empty Wikibase that is in need of a data model and ontology design from scratch can be a liberating prospect for disciplines that defy conventions and do not fit neatly in previously established metadata standards (particularly good case-in-point being contemporary art data [12]). But this can also be an issue for researchers who just want (or are required) to work within an established standard and re-use ontologies maintained elsewhere on the semantic web. Although there are ways to map local Wikibase properties and classes to external ontologies, the internal RDF structure remains “flat” and lacks the semantics needed for more sophisticated reasoning operations over its triplestore [13, 14]. Furthermore there are no formal constraints or validation rules that can be applied to Wikibase’s flat data structure as is [15]. Lastly, there is a lack of out-of-the-box templating possibilities to visually distinguish between different item classes and to improve usability when users are browsing/accessing or entering/editing data on an individual item-level.
So what is to be done?: Mitigation tactics vs redevelopment
An established tradition in open source software (OSS) culture is that if a tool doesn’t perform to user expectations, users have the choice to either find workarounds or they can write a patch, or even an extension of the tool, and submit a pull request for the issue at hand. As a free OSS tool, Wikibase benefits from this OSS culture ethos and its community has been incredibly resourceful in finding workarounds and banding together to develop entirely new features.
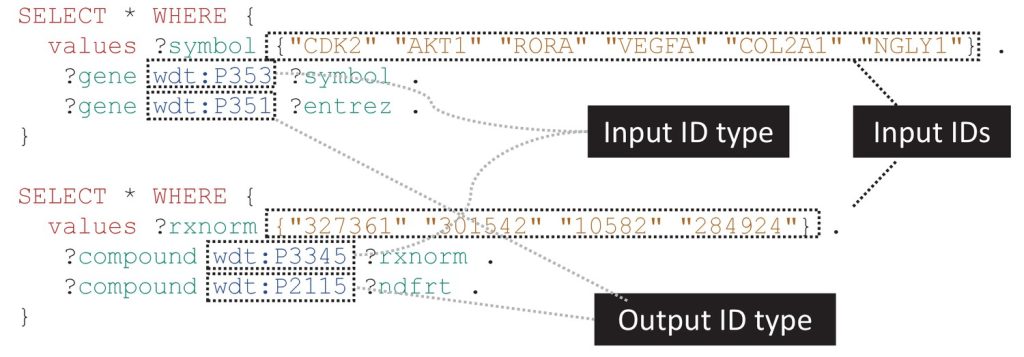
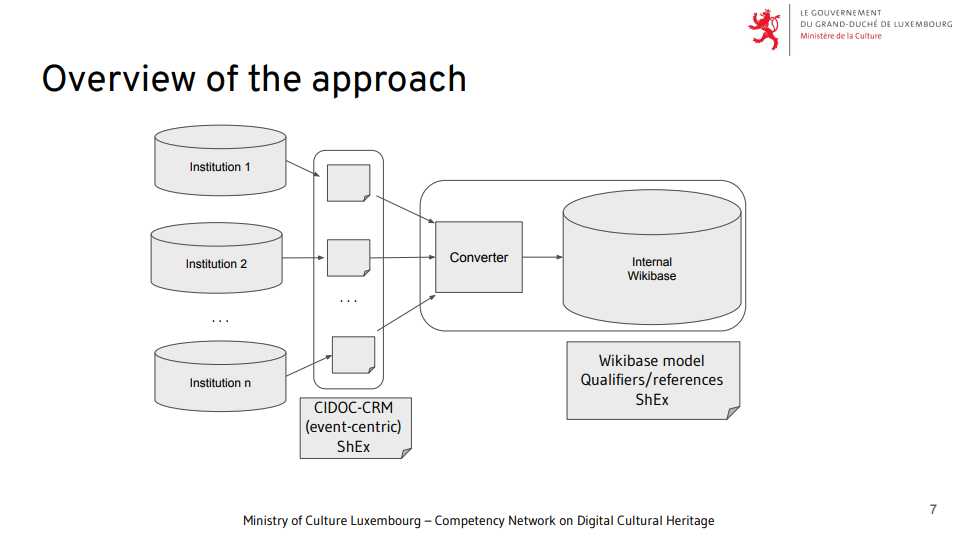
Another example regarding community-led efforts to respond to concrete user needs are new tools being developed to address the need for better templating and data validation in Wikibase. The ShEX-based tools developed by the WESO research group at the University of Oviedo are a good example [20]. Many individual Wikibase (and Wikidata) research projects have also developed a variety of ways to deploy customised item templates both on the level of browsing and displaying information (e.g. WikiGenomes, ChlamBase, ScienceStories), as well as on the level of data entry per entity type (e.g. Wikidata for Digital Preservation). But certainly, more can be done to make this work ready for reuse across the broader community.
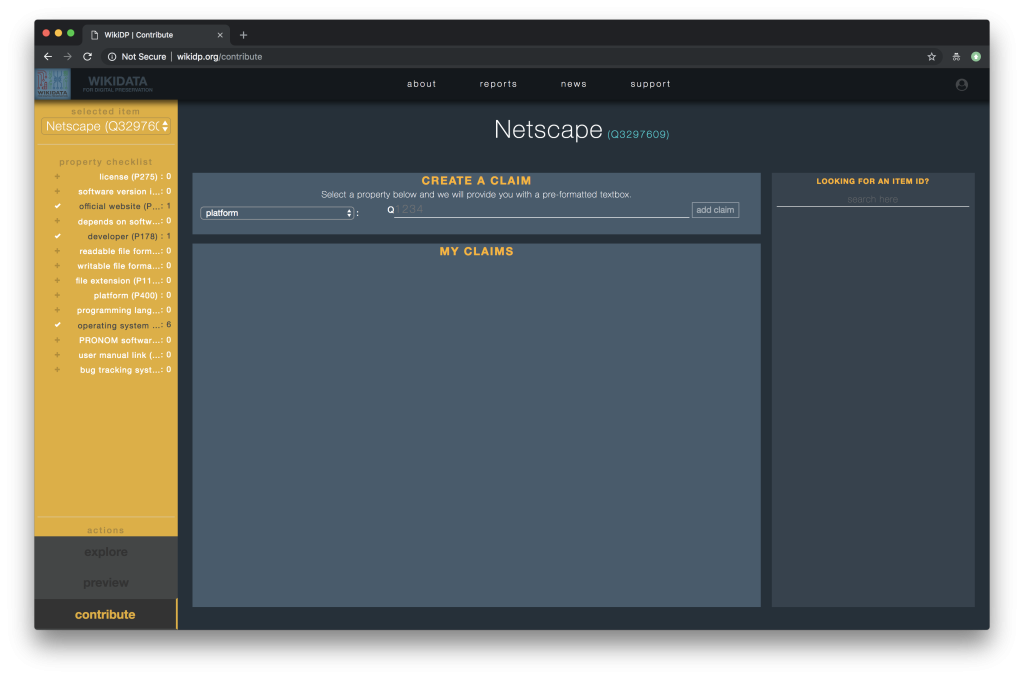
Why Wikibase?: Strength in numbers
Wikibase is a working, albeit imperfect solution for the needs of scientists and researchers managing heterogeneous datasets. At OSL, we believe the strength in numbers is what makes it a sustainable solution in the long term. As of March 2022, these are some statistics confirmed by Wikimedia Germany:
- Wikibase for research: ~63 ongoing projects, and ~10 pre-pilot projects;
- Wikibase in the wild: 148 individual user accounts and 510 instances on WBstack, WMDE’s test cloud infrastructure;
- Dedicated Wikibase staff within Wikimedia Germany: 14 FT staff members;
- Development support in the community: 217 members in the developer Telegram group (182 contributors on Github).
Furthermore, as we’ve shared on this blog before, we are members of the Wikibase Stakeholder Group, where we are directly involved in the development, planning and growth of the Group, alongside 17 institutional members across Europe and North America and many more individual researchers. The Group is actively working on growing developer capacity in the ecosystem around Wikibase, commissioning and developing new Wikibase extensions, and building sustainable new funding models for OSS product development.
Last but not least, it is worth noting that developing any infrastructure (whether a Wikibase instance, or another triplestore) in the context of a research project is tied to (and limited by) grant funding cycles. At the end of a research project, infrastructure often decays. Using Wikibase offers seamless alignment with Wikidata, the latter being a stable infrastructure independent of such funding cycles. Data originally stored in a Wikibase instance can easily be exported and made permanently available on Wikidata. It can of course also live on – in its RDF form – on many other RDF platforms. In short, Wikibase can work as a “proxy” in the research data landscape that allows long-term sustainability of the acquired knowledge [21].
To learn more about how Wikidata and Wikibase can work as complementary services for cultural heritage data more specifically, check out our follow-up blog post.
Acknowledgements
Thanks to my OSL colleagues Ina Blümel and Paul Duchesne, and to WBSG members Dragan Espenschied and Andra Waagmeester for their generous feedback and review of this blog post. Special thanks to Andra for pointing out some gaps in the initial draft, especially the final note on longevity of research infrastructure.
Bibliography
- Rossenova, Lozana. (2021, October 29). Semantic annotation for 3D cultural artefacts: MVP. Zenodo. https://doi.org/10.5281/zenodo.5628847
- Rossenova, Lozana, Schubert, Zoe, Vock, Richard, & Blümel, Ina. (2022, March 7). Beyond the render silo – Semantically annotating 3D data within an integrated knowledge graph and 3D-rendering toolchain. DHd 2022 Kulturen des digitalen Gedächtnisses. 8. Tagung des Verbands „Digital Humanities im deutschsprachigen Raum“ (DHd 2022), Potsdam. https://doi.org/10.5281/zenodo.6328155
- Waagmeester, A. et al (2020). Science Forum: Wikidata as a knowledge graph for the life sciences. eLife 2020; 9:e52614 DOI: 10.7554/eLife.52614
- Thornton, K., Seals-nutt, K., Cochrane, E. and Wilson, C. (2018). Wikidata for Digital Preservation. In Proceedings of iPRES’18, Cambridge, MA, USA, September 24–27, 2018.
- Kapsalis, E. (2019). Wikidata: Recruiting the Crowd to Power Access to Digital Archives. Journal of Radio & Audio Media, 26, 134 – 142.
- Pintscher, L. And Heintze, S. (2021, September 13). Ontology issues in Wikidata. Data Quality Days. Available from: https://commons.wikimedia.org/w/index.php?title=File%3ADataQualityDaysontologyissues.pdf
- Pham, M. et al (2021). Scaling Wikidata Query Service – unlimited access to all the world’s knowledge for everyone is hard. WikidataCon 2021. Available from: https://www.youtube.com/watch?v=oV4qelj9fxM&ab_channel=wikimediaDE
- Mietchen D, Hagedorn G, Willighagen E, Rico M, Gómez-Pérez A, Aibar E, Rafes K, Germain C, Dunning A, Pintscher L, Kinzler D (2015) Enabling Open Science: Wikidata for Research (Wiki4R). Research Ideas and Outcomes 1: e7573. https://doi.org/10.3897/rio.1.e7573
- Zeinstra, M. (2019). Returning Commons Community Metadata Additions and Corrections to Source. Swedish National Heritage Board. Available from: https://meta.wikimedia.org/wiki/File:Research_Report_–_Returning_commons_community_metadata_additions_and_corrections_to_source.pdf
- Shigapov, R. (2021). RaiseWikibase: Towards fast data import into Wikibase. 2nd Workshop on Wikibase in Knowledge Graph based Research Data Management (NFDI) Projects. 29 July, 2021. Available from: https://madoc.bib.uni-mannheim.de/60059/1/29.07.2021-RaiseWikibase-Shigapov.pdf
- Pintscher, et al. (2019). Strategy for the Wikibase Ecosystem. Available from: https://upload.wikimedia.org/wikipedia/commons/c/cc/Strategy_for_Wikibase_Ecosystem.pdf; See also: Wikimedia. (2021). Strategy 2021: Wikibase ecosystem. Available from: https://meta.wikimedia.org/wiki/LinkedOpenData/Strategy2021/Wikibase
- Fauconnier, S., Espenschied, D., Moulds, L. and Rossenova, L. (2018). “Many Faces of Wikibase: Rhizome’s Archive of Born-Digital Art and Digital Preservation.” Wikimedia Blog. 2018. https://wikimediafoundation.org/news/2018/09/06/rhizome-wikibase/.
- As stated by Prof. Dr. Harald Sack during the NFDI InfraTalk presentation on “Wikibase and the challenges and possibilities of knowledge graphs for RDM in NFDI4Culture”. Recording available from: https://www.youtube.com/watch?v=RPMkuDxHJtI
- Still, Wikidata and Wikibase offer some capabilities out-of-the-box that are actually less “flat” than other RDF resources, for example the possibility to attach references or qualifiers to individual triple statements. In addition, it is worth noting that Wikidata contains properties like wdt:P279 and wdt:P31 which are direct translations of rdf:type and rdfs:subclass of. Andra Waagmeester from the Wikibase Stakeholder Group has demonstrated the potential to use CONSTRUCT queries to get the semantics needed for reasoning also in Wikidata, e.g. see this example query: https://w.wiki/4×49
- This is somewhat addressed by an extension – EntitySchema – which can bring machine-readable boundaries to any Wikibase, though the values in statements defined by an entity schema are still not validated apart from data type, e.g. a statement with a property calling for a country can still be (wrongly) populated by a city item, because the only constraint is to add a Wikidata item in the value field associated with the country property.
- Rhizome. (2021). Welcome to the ArtBase Query Service: Federation and Advanced Queries. Available from: https://artbase.rhizome.org/wiki/Query#Federation_and_Advanced_Queries.
- Diefenbach, D., de Wilde, M., and Alipio, S. (2021). Wikibase as an Infrastructure for Knowledge Graphs: the EU Knowledge Graph. ISWC 2021, Oct 2021, Online, France. Available from: https://hal.archives-ouvertes.fr/hal-03353225/document
- Fichtmueller, D. (2021). Using Wikibase as a Platform to Develop a Semantic Biodiversity Standard. 1st NFDI Wikibase Workshop, 23 February, 2021. Available from: https://docs.google.com/presentation/d/1i91OB9xPZVVovd8c7Cm2sOglQLM8CEeZed8grdVaFwU/edit
- Labra Gayo, J. E., et al. (2021). Representing the Luxembourg Shared Authority File based on CIDOC-CRM in Wikibase. SWIB 2021, 29 Nov–03 Dec 2021, Online. Available from: https://www.youtube.com/watch?v=MDjyiYrOWJQ&ab_channel=SWIB
- Labra Gayo, J. E. (2021). Entity schemas tools at WESO. Wikibase Stakeholder Group Monthly Community Meetup, 20 May 2021. Available from: https://docs.google.com/presentation/d/1wizillfIQ6oZdU4TLxk69snwEhHji004MOlyj8hlTC4/edit#slide=id.gdb3b447ec8_0_97
- Waagmeester, Andra. In email conversation with the author, March 14, 2022.

Dr. Lozana Rossenova ist Mitarbeiterin im Open Science Lab der TIB und arbeitet im Projekt NFDI4Culture in den Bereichen Datenanreicherung und Entwicklung von Wissensgraphen. // Dr Lozana Rossenova is currently based at the Open Science Lab at TIB, and works on the NFDI4Culture project, in the task areas for data enrichment and knowledge graph development.
Really nice blog post, however, I might not agree with the following phrase:
„Although there are ways to map local Wikibase properties and classes to external ontologies, the internal RDF structure remains “flat” and lacks the semantics needed for more sophisticated reasoning operations over its triplestore“.
IMO the contrary is the case. There where regular triple stores use the RDF triple as the basic form, a Wikibase atomic statement extends that model with qualifiers and references. This is rendered in a quite hierarchical RDF structure [1], which can be imported in any other triple store. The qualifiers and reference is more an enrichment to the „flat“ model of standard triple stores. There is also an alignment with semantics that are used in reasoning [2]. So this rich RDF rendering and the mappings do allow reasoning.
There is however another issue that might prevent optimal (public) reasoning on Wikidata and that is that many ontologies use a restrictive reuse license which will lead to license stacking [3]. I am not a lawyer, but my understanding is that it is fine to ingest wikidata and do reasoning locally provided the license requirements are met when results are published. However, when it comes to ingesting the ontologies in Wikidata, restrictive licenses of those ontologies prevent reuse in wikidata or any other public resource. We are simply not allowed to add ontological relationships needed for reasoning directly in wikidata, since they are the result of a creative process and thus fall under copyright. Here the solution might be to only create a mapping in wikidata, which would allow users to fetch the ontological relationships from the primary source.
IMO wikidata is not an ontology nor a collection of ontologies, It is a linked data source that does provide links to ontologies. These links make those ontologies more findable and also allow reasoning on wikidata data. Just download the ontology from its primary source.
[1] https://www.mediawiki.org/wiki/File:Rdf_mapping-vector.svg
[2] https://www.wikidata.org/wiki/Wikidata:Relation_between_properties_in_RDF_and_in_Wikidata
[3] https://mozillascience.github.io/open-data-primers/5.3-license-stacking.html
Dear Andra,
Thanks for this detailed and relevant comment! Indeed the licensing issue is important to raise, and I’m glad you bring it up, since I failed to mention it in this blog post.
With regards to the richness of the RDF structure, I put some additional details in footnote #14, but thanks for providing further sources to back this up!
Regards,
Lozana