Projekt TAPIR: Mit der Macht der PIDs
Einleitung
Eine wiederkehrende Verpflichtung von Forschungsinstitutionen ist die Berichterstattung, um verschiedenste Interessengruppen mit aktuellen Informationen zum Forschungsgeschehen an der Einrichtung zu versorgen. Der Prozess der dafür notwendigen Datenaggregation und -aufbereitung ist sowohl zeit- als auch arbeitsaufwändig. Im Projekt TAPIR erproben wir daher teilautomatisierte Verfahren zur Forschungsberichterstattung im Kontext universitärer und außeruniversitärer Forschung. Wir gehen der Frage nach, inwiefern die dazu erforderliche Datenaggregation auf Basis offen verfügbarer Forschungsinformationen mittels persistenter Identifikatoren durchgeführt werden kann.
Offene Datenquellen
Zu Beginn des Projekts haben wir dafür zunächst eine Übersicht von aktuellen Datenquellen aufgestellt, aus denen wir offene Daten über Forschungsobjekte via einer API automatisiert abfragen könnten. Ein guter Startpunkt war hier das Registry of Scientometric Data Sources (ROSI), welches bereits in einem vorherigen Projekt der TIB zusammengetragen wurde. Allerdings hatten sich seit den letzten Eintragungen noch einige weitere Datenquellen aufgetan und so haben wir als Dankeschön und um unsere zusätzlichen Funde nachnutzbar zu machen, ROSI mit acht neuen Einträgen aktualisiert, darunter ROR, ORCID und OpenAlex.
Persistente Identifikatoren
Aus dem Fundus an offenen Datenquellen kamen für uns nur diejenigen in Frage, welche eine Abfrage von Forschungsinformationen mittels persistenter Identifikatoren (PIDs) ermöglichen. Der Vorteil bei der Nutzung von PIDs ist, dass diese im Vergleich zu Namen, Titeln oder Bezeichnern eindeutig und dauerhaft sind und damit keine Notwendigkeit besteht, die abgefragten Daten vor ihrer Weiterverarbeitung zu disambiguieren. Des Weiteren sind PIDs (i.d.R.) mit Metadaten verknüpft, die die referenzierten Entitäten beschreiben und wiederum auf andere PIDs verweisen können. Dies ermöglicht Verbindungen zu anderen Objekten eindeutig herzustellen und abzubilden, wie es bei sogenannten PID-Graphen der Fall ist.
Abfragen
Fassen wir zusammen: Ziel ist es, die Forschungsaktivitäten einer Institution in Standard-Berichten abzubilden und dazu PIDs aus offenen Datenquellen zu nutzen. Gegeben ist also ein PID für die Organisation. Gesucht ist eine Menge an PIDs, die jeweils einen Forschungsoutput der Organisation eindeutig kennzeichnen. Da der Forschungsoutput i.d.R. eher mit Autor:innen verbunden ist als mit einer Organisation, wird noch ein Zwischenschritt benötigt, der die zu einer Organisation gehörenden Forschenden ermittelt, und darüber dann von den Forschenden jeweils den Forschungsoutput. Die Abfrage der Daten verläuft entsprechend zweistufig, einmal Organisation-Personen und dann weiter Person-Werke. Die Organisation ist dabei über ihre ROR, eine Person über ihre ORCID und ein Werk über seine DOI identifiziert.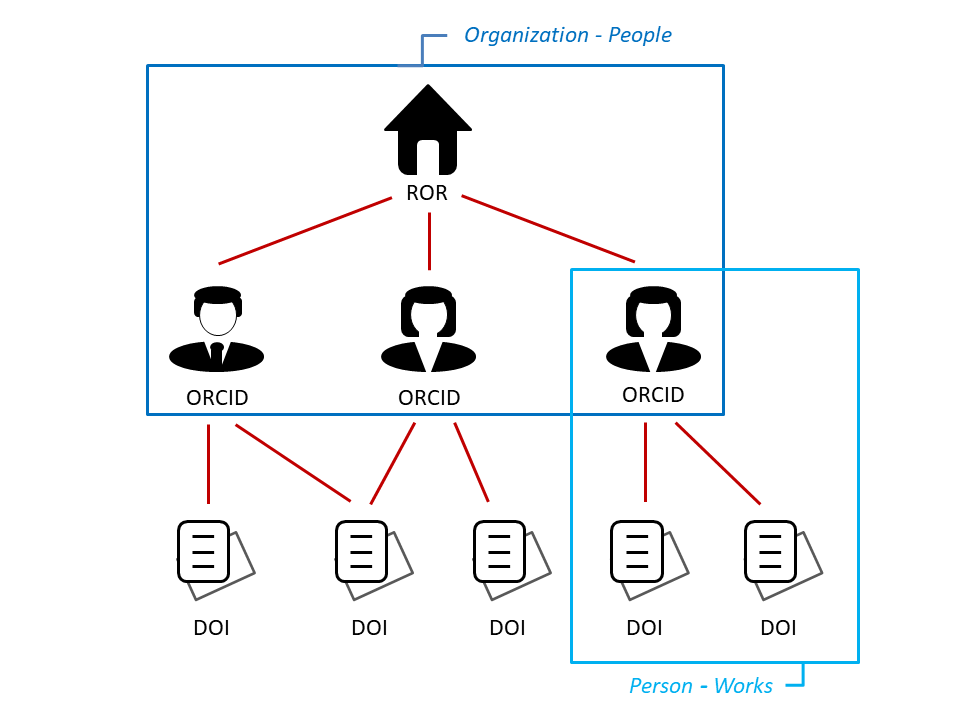 Datenquellen, die beide dieser Abfragen ermöglichen, sind u.a. der FREYA PID Graph, ORCID und OpenAlex. Für die Verbindung Person-Werke haben wir zusätzlich Crossref als einen der größten DOI-Anbieter dazugenommen. Alle Abfragen sind in nachnutzbaren Jupyter Notebooks beschrieben und unter https://github.com/Project-TAPIR/pidgraph-notebooks zu finden. Der dort hinterlegte Code kann über den Web-Service Binder direkt im Browser ausgeführt werden und mit der ROR ID der eigenen Institution oder der eigenen ORCID ausprobiert werden. Ein Button, der die Notebooks in Binder öffnet, ist in der Beschreibung (README) zu finden.
Datenquellen, die beide dieser Abfragen ermöglichen, sind u.a. der FREYA PID Graph, ORCID und OpenAlex. Für die Verbindung Person-Werke haben wir zusätzlich Crossref als einen der größten DOI-Anbieter dazugenommen. Alle Abfragen sind in nachnutzbaren Jupyter Notebooks beschrieben und unter https://github.com/Project-TAPIR/pidgraph-notebooks zu finden. Der dort hinterlegte Code kann über den Web-Service Binder direkt im Browser ausgeführt werden und mit der ROR ID der eigenen Institution oder der eigenen ORCID ausprobiert werden. Ein Button, der die Notebooks in Binder öffnet, ist in der Beschreibung (README) zu finden.
Ausblick
Im nächsten Schritt geht es im Projekt TAPIR darum, die abgefragten Daten aus den verschiedenen Datenquellen zu evaluieren. Dazu werden wir ihre Abdeckung in Bezug auf Personen und publizierte Werke einmal mit intern erstellten verifizierten Listen, die an den am Projekt beteiligten Institutionen TIB und Universität Osnabrück angefertigt wurden, und dann noch einmal untereinander vergleichen.
Alle Entwicklungen können Sie auf unserer Projekthomepage https://projects.tib.eu/tapir/ oder auf unserem Twitter Kanal project-tapir mitverfolgen.
Image: “Color comp” by Pablo Stanley. The Blush open license, illustrations for commercial and non-commercial purposes. https://blush.design/license
0 Antworten auf “Projekt TAPIR: Mit der Macht der PIDs”