Microsoft Academic – eine bedeutende Datenquelle versiegt
Microsoft hat bekannt gegeben, dass der Microsoft Academic Graph zum Ende des Jahres 2021 eingestellt wird. Was bedeutet das? Warum ist das für Forschende und Forschungseinrichtungen wichtig?
Der Microsoft Academic Graph ist die Datenbasis hinter Microsoft Academic, eine der umfassendsten wissenschaftlichen Suchmaschinen. Die Daten werden von Microsoft jedoch nicht nur für diesen hauseigenen Suchdienst genutzt. Im Gegensatz zum bekannten Konkurrenten Google Scholar hat man sich dazu entschieden, die Daten für Dritte zur Verfügung zu stellen. Und dies wurde in den letzten Jahren vielfach in Anspruch genommen. Ein Grund dafür ist sicherlich, die Größe von Microsoft Academic. In einer aktuellen Untersuchung des Centre for Science and Technology Studies (CWTS) wurden verschiedene bibliographische Datenquellen untersucht, und die folgende Abbildung spricht – ungeachtet einiger von den Autoren vorgebrachter Einschränkungen bezüglich der Vergleichbarkeit – für sich.
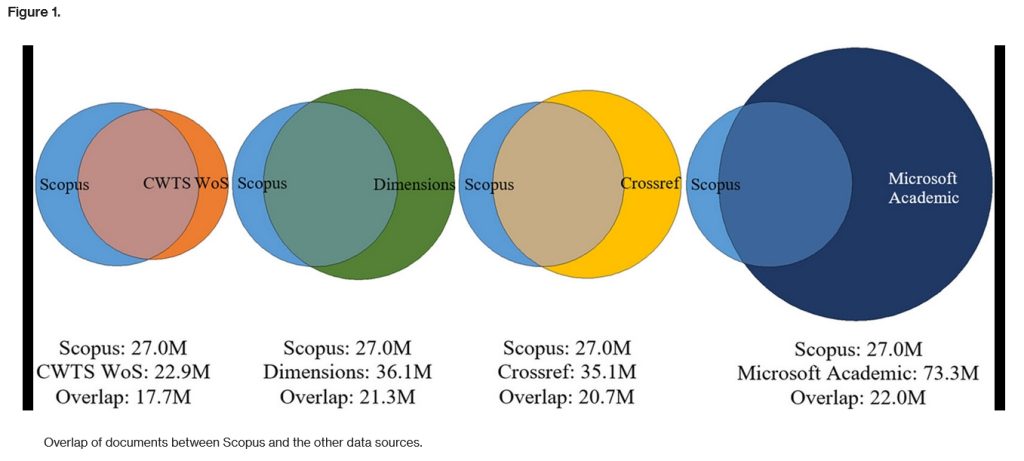
Microsoft Academic ist also eine riesige und dazu noch via Schnittstelle und als Dump verfügbare Datenquelle. Dazu ist sie für bibliometrische Analysen aufbereitet und dokumentiert. Die Relevanz dieser Daten für die Wissenschaft ist leicht ersichtlich. Die beiden diesen Dienst beschreibenden Publikationen wurden (laut Microsoft Academic) mehr als 500 bzw. 1700 Mal zitiert.
In der Ankündigung zur Einstellung des Dienstes erwähnt Microsoft einige Alternativen. Schaut man sie sich genauer an, stellt man fest, das einige davon zumindest zum Teil auf Microsoft Academic aufbauen, z.B. Semantic Scholar oder The Lens. Die schon vorhandenen Daten werden vermutlich weiter genutzt werden können, auch Dank Initiativen wie MAKG, wo eine Kopie samt Schnittstellen bereit gestellt wird. Aktualisierungen werden jedoch in absehbarer Zeit nicht mehr gemacht.
Diese Meldung hat große Auswirkungen auf all jene, die sich auf Microsoft Academic als Datenquelle verlassen haben. Dass es keine gute Idee ist, sich auf die Verfügbarkeit einer proprietären Datenquelle zu verlassen, wird hier klar ersichtlich.
An der TIB beteiligen wir uns daher an verschiedenen Initativen zur Verbesserung offener Datenquellen wie der Initiative for Open Abstracts. Im gerade gestarteten Projekt OPTIMETA werden wir Open-Access-Zeitschriften dabei unterstützen, offene Zitationsdaten und raumzeitlichen Metadaten frei verfügbar zu machen. Im Projekt TAPIR erproben wir die Nutzung von offenen Forschungsinformationen für die Forschungsberichterstattung, mit unseren Partnern von der State Scientific-Technical Library of Ukraine (SSTL) diskutieren wir über FAIR Research Information in Open Infrastructures. Für Forschungseinrichtungen, Bibliotheken und auch Forschende kann der aktuelle Vorfall eine Erinnerung daran sein, dass es sich lohnt, an offenen Alternativen zu proprietären Forschungsinfrastrukturen zu arbeiten.
Beitragsbild von Aleksandar Cvetanović auf Pixabay

... arbeitet im Open Science Lab der TIB und beschäftigt sich dort (überwiegend) mit offenen Forschungsinformationen und Open Science. Weitere Informationen: https://tib.eu/christianhauschke
„Das (sic!) es keine gute Idee ist, sich auf die Verfügbarkeit einer proprietären Datenquelle zu verlassen, wird hier klar ersichtlich.“
Sorry, aber diese Darstellung stellt den Sachverhalt doch verzerrt dar. Die Daten sind frei nachnutzbar, ein Teil der Software auch. In der Darstellung von Microsoft war es ein erfolgreiches „research project“, von dem viele andere profitiert haben. Das kann man anerkennen und das muss man erst mal nachmachen. Ich möchte nicht wissen, wie viele Projektleichen das deutsche Bibliothekswesen schon produziert.
Ein großer Teil des Werts von Microsoft Academic liegt darin begründet, dass die dort erzeugten Daten nicht nur umfassend und von guter Qualität sind, sondern dass sie auch stets aktuell gehalten wurden. Baut man Dienste oder Analysen auf diesen Daten auf, ist dies nur möglich, sofern der gewünschte Zeitraum abgedeckt wird. Sowohl bibliometrische Analysen als auch Discovery-Systeme oder Forschungsinformationsssyteme müssen sich nun umgucken.
Die Anerkennung für die Leistung des Microsoft-Teams ist übrigens absolut vorhanden. Der MAG ist nicht umsonst so beliebt. Genau daher ist es ja auch ein so gravierender Einschnitt, wenn ausgerechnet dieses Projekt beendet wird. Die Non-Profit-Organisation Our Research wird sich übrigens um einen Ersatz für den MAG bemühen: We’re building a replacement for Microsoft Academic Graph.
PS: Vielen Dank für den Hinweis auf den Tippfehler.