Semantic Publishing: The Future Open Textbook – a Contribution to NFDI4Culture
Semantic Publishing is a new open-source software research project contributing to the techstack for the creation of multi-format textbooks. A new generation of textbooks that includes modern Open Science digital objects, has semantic layers for structure and meaning, and packaging for interoperability. We are focusing on a specific book type ‘the textbook’ as an integrated part of MOOCs. The project is based at the Open Science Lab – TIB and contributes to the German consortium of the National Research Infrastructure for Culture (NFDI4Culture).
Motivation
The goal of the project is to contribute to making a new type of book that combines technology from the long history of the book with the Open Web. Essential to this new book is full-automation of workflows and being machine interpretable. (ORKG, 2019) As an example archives on the web can potentially provide images for reuse with a manifest including DOIs and taxonomies for automatic inclusion in a publication – but in working practice it’s not the norm at present and not a fluid workflow. Semantic publishing is the pathway to bring in more connected practices, by leveraging open-source software and existing open infrastructures, to connect content repositories and Open Science services.
This type of book is in fact not new but was imagined nearly fifty years ago at Xerox PARC California by Alan Kay in his 1972 paper ‘A personal computer for children of all ages’ (Kay 1972) called the Dynabook. As for the ‘digital artifacts’ to be included inspiration is taken from Yuk Hui’s book On The Existence of Digital Objects (Hui 2016) which points to the thinness of meaning in computational systems and look to utilise knowledge graph technologies like Wikidata to make a richer digital object – the micro publication – than those scrutinised in Hui’s philosophical critique.
Semantic Publishing
For our context Semantic Publishing for books means packaging as many modern Open Science digital objects as possible into the book – IIIF image deep zooms, 3D models, semantic video, smart images, annotation, and computational publishing data objects à la Jupyter Notebooks. Then we add two semantic layers to the book to make it machine interpretable. A layer to identify ‘parts of a book’ – covers, front matter, down to granular items such as citations, etc. Then a layer for inferring meaning, combining: PIDs such as DOIs, Wikidata/Wikibase, ontologies, cryptographic IDs, and knowledge graphs. The Semantic Publication then needs binding to follow the technology history of the codex and become a book and not just a scattered bunch of data. For this purpose we combine the W3C Publication Manifest (W3C 2020) and WebBook Level 1 Unofficial Proposal Draft, (Glazman 2018) although these will need extending to deal with our new additions and media types.
Micro-publications (Blümel, Heller, and Sohmen 2020) is a concept introduced by the Open Science Lab (OSL) team of granularising the publication into digital objects that can be assigned DOIs and also authorship with ORCID IDs or as decentralised Linked Research (Capadisli 2019) – IIIF image embeds, 3D model inclusions, etc.
The Semantic Publishing project has a specific technology stack it is combining as a platform that will be iteratively developed to realise the ideas, but it is primarily about data and workflow interoperability underpinned by a combination of open W3C standards – where possible – to allow any platform to carry out semantic publishing.
The future open textbook
The ambition is to build on OSL’s previous textbook research and refine a workflow that integrates open textbooks as modular and fully integrated parts of MOOC teaching modules using Moodle.

The OSL has been running book sprints – collaborative authoring book productions – since 2014. This year the OSL has collaborated with the Academy for Public Health in Dusseldorf to produce nine textbooks on public health – all using the book sprint method and some with MOOC modules.
In research terms an important ‘knowledge management’ lesson has been learned from the book sprint process is the need for a better connection between research literature and the textbook – with the textbook being the more stable, trustworthy and digestible knowledge form. The current paradox is that we have research literature which is complex and moving too fast – with over production – and conversely textbooks moving too slowly and being out of date. Our question in the research will be how to support up-to-date textbook creation.
| Research literature | Review processes | Textbook |
| Fast moving / unstable | More or new review processes needed | Moving too slowly & out of date |
https://www.youtube.com/watch?time_continue=2&v=DvlhK6vX2Io&feature=emb_logo
Existing software for multi-format publishing
The OSL has already made significant progress on open-source R&D to overcome the full automation of the production workflow for Open Access multi-format books, to produce and distribute the following – ebook, print-on-demand, screen PDF, webbook, website, and an interoperable source. The full automation has not been fully resolved but the outstanding issues are known, situating the Technology Readiness Levels (TRL) as TLR 3 (experimental proof of concept) going to TLR 4 (validated in lab).
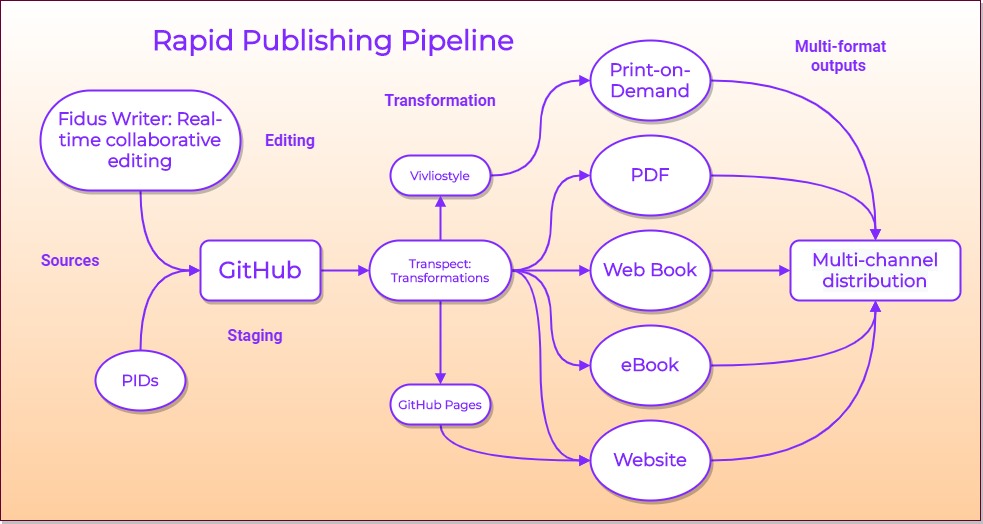
The technology stack has been focused on using GitHub as a publishing platform. The beauty of using GitHub as a publishing location is that it’s free, on the open web, and leverages a huge infrastructure. Git or GitLab can also be used. We use Fidus Writer as an academic real-time collaborative word processor for authoring. For multi-format typesetting we use Vivliostyle a CSS typesetting engine using W3C CSS Paged Media.
Creating a manifest and packaging the book – its binding of sorts – was our most recent addition (Thanks to Shinyu Murakami of Vivliostyle) and it is these that will be expanded to accommodate all the new Semantic Publishing additions to the book.
Methods
The research will be carried out by running a series of case studies and rapid prototyping using design research methods. This is aided by having an infrastructure already in place with our – GitHub, Fidus Writer, and Vivliostyle workflow – where dedicated experiments can be carried out for example with IIIF images from archives or by running live code with Jupyter Notebooks for 3D models.
The cultural realm for our case studies will relate to architecture as TIB Library represents architecture in NFDI4Culture consortium. In the context of architecture the OSL has a separate research project addressing the digitisation of the locations of Gestapo crimes in Lower Saxony ‘Traces of the past: making crimes of the Gestapo digitally visible’. For this archiving project potential use cases will be explored.
The Semantic Publishing research will be carried out using the Open Notebook philosophy of Jean-Claude Bradley. Using the Open Notebook method everything is posted publicly with the purpose of finding the bug and fixes and to facilitate the quickest way to create high-quality content and to give a feeling of communal ownership.
Conclusion – Invite
As mentioned the Semantic Publishing research is about contributing to the techstack that makes up the next generation of connected textbooks and in the community spirit of open-source and Open Science the project is open to knowledge sharing to find the most effective ways to realise the goal of a new type of book. A public Git repository can be found here on the NFDI4Culture GitHub space.
References
ORKG. 2019. ‘About ORKG’. https://projects.tib.eu/orkg/.
Kay, Alan. 1972. ‘A Personal Computer for Children of All Ages’. In A Personal Computer for Children of All Ages. Boston. https://mprove.de/visionreality/media/kay72.html.
Hui, Yuk. 2016. On the Existence of Digital Objects. Electronic Mediations 48. Minneapolis: University of Minnesota Press. https://www.upress.umn.edu/book-division/books/on-the-existence-of-digital-objects.
W3C. 2020. ‘Publication Manifest’. https://www.w3.org/TR/pub-manifest/.
Glazman, Daniel. 2018. ‘WebBook Level 1 Unofficial Proposal Draft’. http://glazman.org/e0/webbook.html.
Capadisli, Sarven. 2019. ‘Linked Research on the Decentralised Web’. 29 July 2019. https://csarven.ca/linked-research-decentralised-web.
Blümel, Ina, Lambert Heller, and Lucia Sohmen. 2020. ‘Some things we care about for NFDI4Culture – Or: We want better tools and workflows for annotating images and 3D models!’ TIB-Blog (blog). 10 September 2020. /2020/09/10/some-things-we-care-about-for-nfdi4culture-or-we-want-better-tools-and-workflows-for-annotating-images-and-3d-models/.
![]()
The Consortium for Research Data on Material and Immaterial Cultural Heritage (NFDI4Culture)
The aim of NFDI4Culture is to establish a demand-oriented infrastructure for research data on material and immaterial cultural assets. This includes 2D digitised reproductions of paintings, photographs and drawings as well as 3D digital models of culturally and historically important buildings, monuments or audiovisual data of music, film and stage performances. Concept and structure of the consortium were developed over two years in an open process and in close cooperation between 11 professional societies, 9 supporting institutions and 52 partners. The consortium addresses the needs of a broad spectrum of disciplines from architecture, art, music, theatre, dance, film and media studies.

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.
0 Antworten auf “Semantic Publishing: The Future Open Textbook – a Contribution to NFDI4Culture”