The Future Open Book
Rapid publishing for public health books against COVID-19
The article covers a case study of the barriers to be overcome to fully automate the production workflow for Open Access multi-format books, to produce and distribute the following – ebook, print-on-demand, screen PDF, webbook, website, and an interoperable source.
This blogpost was written to accompany the presentation at the Japanese ‘Vivliostyle User/Dev Meeting 2020 Autumn’ 24 October 2020 13:00 JST (04:00 UTC) – 17:10 JST (08:10 UTC).
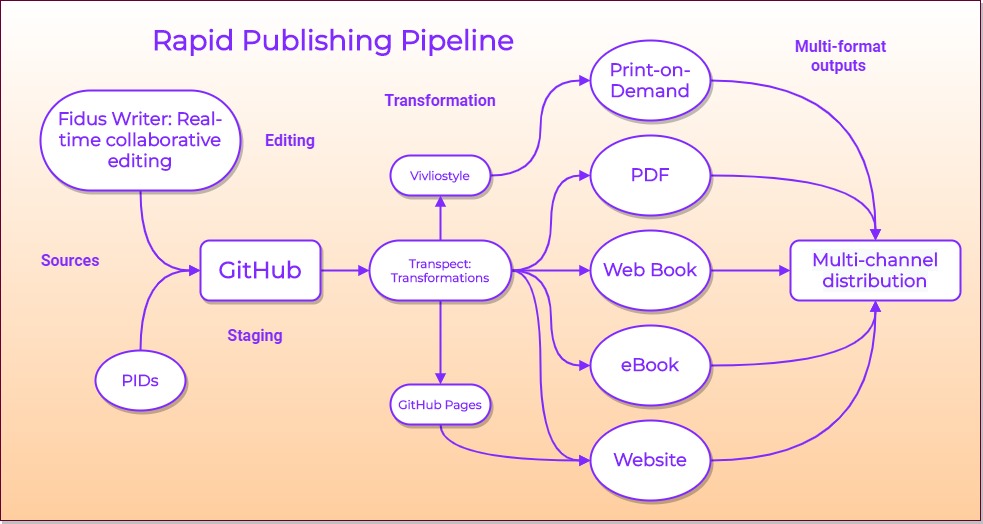
The case study
The case study involves producing eight book sprints for training manuals, some with MOOC modules, for the Academy of Public Health in Dusseldorf (Germany) which was run as a research cooperation with the Open Science Lab, TIB – German National Library of Science and Technology.
Motivation
We are using the book as a technology and social practice within healthcare knowledge management. For example the ‘book sprint’ method of bringing together health professionals to write and publish a textbook collaboratively means knowledge can be updated in real-time, with full academic quality standards, and bypass publishers outdated, slow, and expensive workflows.
Under normal conditions a medical expert would have to buy copies of a textbook they had contributed to if it wasn’t licenced as Open Access. Now instead the book is instantly on GitHub, freely available as multi-format and on your mobile, and automatically globally available via Ingram’s print-on-demand service Lightning Source on Amazon and many other retailers sites for next day print delivery.
The vision of the technical investigation of the ‘Future Open Book’ is based in Open Science considerations, technical and social, of opening up the whole knowledge life cycle not just Open Access books and literature, but of: open data, persistent identifiers, knowledge graphs, linked open data, taxonomies, and social justice questions of knowledge equity and diversity of participation in scholarship.
To address these ‘Open Science’ concerns we will cover our next steps in opening the book which is ‘Semantic Publishing’ and how the book can interface Open Science services: sharded DOIs, cryptographic IDs, Linked Open Data, image deep zooming IIIF, 3D and simulations, live data processing, e.g., Jupyter Books, etc.
Our major challenges
The cornerstones of our challenges are:
- Give the authors an online Word like experience that works for having twelve plus authors on a document in real time at one time. Our contributors are busy healthcare workers who want to focus on their ideas and not have to be reskilled in yet another Markdown variation. Markdown works well for many researchers but it’s not appropropriate for our medical authors.
- Full automatic typesetting of at least five output formats with 100% validation in what we term PROs (publication ready outputs). PROs means an output format has to be 100% ready for distribution.
Challenges
- CSS Typesetting – heuristic automatic typesetting of a whole book
- Multi-format CSS typesetting in one CSS and resource bundle
- Content encoding and validation – ensuring the source code has enough information to work for all outputs
- Using GitHub as a publishing platform
- Git and staging
- Manifest reading order issues with multi-format publishing (ebooks have front matter at the back of the book)
- Packaging and file structure – using W3C packaging and manifest open standards. Lightweight Packaging Format (LPF) and Publication Manifest
- Language translation and forking – Weblate
- Metadata management and distribution
- Multi-channel distribution: GitHub/Lab, trade ISBN, DOI, Amazon and other online retailers, ebook trade, PoD, academic repository, Archive.org, etc.
The technology stack
We aim to stay within W3C open standards frameworks, but since the W3C doesn’t understand enough about academic publishing and its workflows this isn’t completely possible. As examples HTML doesn’t have a table caption as for web people tables are for grouping content, not displaying rows of data.
All code is OSI open-source compliant licenced.
- Fidus Writer – online academic word processing
- GitHub and GitHub Pages – staging, data storage, web serving
- Vivliostyle – CSS Typesetting and serving and PDF generation via Chrome browser
- Paged Media CSS – CSS Paged Media Module Level 3
- Packaging – Lightweight Packaging Format (LPF) W3C
- Manifest – Publication Manifest W3C (co-exists with Webbook) WebBook Level 1 Unofficial Proposal Draft, 2 February 2018
- Source – XHTML / unzipped EPUB
- Interoperability – MECA https://www.manuscriptexchange.org/
Multi-format typesetting
The attraction of multi-format typesetting is speed and lowering costs. Also for our textbook book types the modular nature of the publications is suited to this type of automation.
This part of the workflow contains the largest amount of problems to be overcome and where the greatest effort has had to be applied.
The objective is to fully automate the process so that a graphic designer doesn’t have to manually layout each page and that the expensive Adobe tool kit can be removed from the workflow.
A designer is still needed to create templates, but as manual typesetting was removed by Desktop Publishing in the 1980s, so the book designer’s role will change again.
We are looking to see if we can create a Bootstrap like model of designing where the designer can work with a set of code libraries, but this is still a long way off. One such project was Blitz eBook Framework, now discontinued (July 2020).
We have to use three typesetting tracks:
- eBook;
- CSS Typesetting for web, PDF and PoD, and;
- website Webbook typesetting.
A major issue is that the book becomes unstable and complex when it becomes multi-format and the publishing industry and standards bodies have done very little to resolve the situations, in fact they have hindered the situation, with little care for the book as a technical object.
What are covers? What is a table of contents? How to exclude items from the ToC? What is a page? How do I reference a page number? If page size changes hot to recalculate ToC page numbers automatically? How do I generate my page folios? Does the web browser support hyphenation in my language? Why can’t I create a blank page? Why do tables not have table descriptions? Have image replacements for tables that can’t display in eBooks? How to get references to display as end of page, end of chapter, end of book, as pop up?
GitHub as a publishing platform
Our way forward, after a series of messy experiments, is to use an uncompressed EPUB file on GitHub that contains multiple XHMTL files. The EPUB will be modified to comply with the WebBook Level 1 Unofficial Proposal packaging. Then we use Paged Media CSS to render the book via GitHub pages using Vivliostyle CSS typesetting JavaScript. The Vivliostyle setup allows us to save a PDF from the Chrome browser back to GitHub. These same XHTML files can simultaneously render a website on GitHub pages. The EPUB is generated straight out to GitHub from Fidus Writer.
The current process has some manual steps such as browser PDF rendering.
The beauty of using GitHub as a publishing location is that it’s free, on the open web, and leverages a huge infrastructure. Git or GitLab can also be used.
Packaging and manifest
A book by definition is a discrete object and needs some bounding, but how is this maintained on the open web. This is where open standards should come into play, but it appears that there is no clear standard that has been adopted, either as a de jure or de facto standard yet.
The primary objective of packaging is to keep everything intrinsic to a book in one place, together. Sounds simple but it can be hard to know where to make the boundaries, with something that needs to exist over time.
Currently we have adopted WebBook Level 1 Unofficial Proposal for packaging from Daniel Glazman Co-Chair 2008-15 of the W3C CSS Working Group. This approach would be combined with the W3C Publication Manifest and be informed by W3C Lightweight Packaging Format.
These types of conventions are needed – we think – to allow for more complexity, and media and data sources to be used as is the case in our area of Open Science.
At a very basic level, we simply need different reading orders in a manifest, and to make some content available only in specific formats – like a ‘back cover’ for print-on-demand but not in ebook.
Metadata and content distribution
In metadata and multi-channel distribution we have not been able to resolve issues yet or find a technical solution to suit our needs. With metadata we have authoring, storage, and distribution challenges. With multi-format distribution the challenges are the variety of systems we need to distribute as well as collection of usage stats and reporting on revenues.
Semantic publishing
Our next challenges which are just over the horizon are bundles up in what we are terming ‘Semantic Publishing’. This covers the structure of the parts of a book and its digital objects. It also includes the inference of meaning and being machine readable.
For academic purposes this means using DOIs to isolate chapters, or DOI sharding to go down to a page or string of text, or to identify images or data used in a publication.
We will use media types like video from semantic sources, image deep zooms using IIIF, 3D, and code simulations from Jupyter Notebooks.
We would also use Wikidata and Wikibase to create Linked Open Data representations of a publication.
Also in the Open Science field there is ‘computational publishing’ where packaging goes up to the level of including full compute environments for VM instantiation such as in Kubernetes.
Conclusion
What is described in the case study is a work in progress but one that has moved beyond a proof of concept. The major issues in automated multi-format typesetting and using GitHub as a publishing platform have been identified and are being resolved.
All of this work has to be credited to my TIB and Akademy colleagues, as well as the members of Fidus Writer, Vivliostyle, and Interpunct Studios. Thanks also goes to Axel Dürkop of Modernes Publizieren Programm Hamburg Open Science (HOS); Daniel of MJT and Darron of kewl.org, and Lisa and Johannes of Endocode.
Links
GitHub – Akademie für Öffentliches Gesundheitswesen in Düsseldorf – https://github.com/akademie-oeffentliches-gesundheitswesen
Rapid Collaborative Health Publishing, Open Science Lab, TIB – https://github.com/TIBHannover/Rapid-Collaborative-Health-Publishing

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.
0 Antworten auf “The Future Open Book”