NLP Contributions Graph: A Call for Participation
In the tipping scale of activities toward the digitalization of scholarly articles, next-generation digital library frameworks such as the Open Research Knowledge Graph, targeting scholarly contributions’ highlights, are already here! We have created the NLPContributionGraph Shared Task that formalizes the building of such a scholarly contributions-focused graph over Natural Language Processing articles as an automated task. If you are eager to build a machine learner, we have the annotated scholarly contributions’ graph data for you – come join us in this endeavor!
Search has long been revolutionized by knowledge-graph-powered services such as the Amazon Marketplace in e-commerce, or Open Street Maps in the cartography and navigation services domains, to name just two examples. One could say inspired from such KG success stories in the general domain, such technology is now being realized over scholarly knowledge as well. In this vein, we highlight TIB’s project Open Research Knowledge Graph (ORKG) that advocates for representing scholarly articles’ contributions in knowledge graphs and that, as a next-generation digital library platform, stores and publishes such graphs as persistent knowledge items. You can browse the ORKG digital library and its scholarly knowledge here!
Since scientific literature is growing at a rapid rate and researchers today are faced with a publications deluge, it is increasingly tedious, if not practically impossible to keep up with the research progress even within one’s own narrow discipline. The ORKG then is posited as a solution to the problem of keeping track of research progress minus the cognitive overload that reading dozens of full papers impose. It aims to build a comprehensive knowledge graph that publishes just the research contributions of scholarly publications per paper where the framework can then intelligently compute paperwise or aggregated scholarly knowledge highlights for researchers.
Naturally, then, one wonders what information should be captured in such scholarly contributions’ knowledge-focused graphs? Within the SemEval 2021: NLPContributionGraph (NCG) Shared Task, we seek both to answer and to discover better answers to this question. We have formalized a scholarly contributions-focused graph model over NLP (natural language processing) scholarly articles that will be applied to annotate hundreds of NLP articles for their contributions. The corpus will be freely released to the NCG task participants, based on which they will be able to train and test automated machine learners. In essence, such systems will read “contributions” information in a subject-predicate-object structured format to be integrable within Knowledge Graph infrastructures such as the ORKG. The corpus annotation data elements will include: (1) contribution sentences – a set of sentences about the contribution in the article; (2) scientific terms and relations – a set of scientific terms and relational cue phrases extracted from the contribution sentences; and (3) triples – semantic statements that pair scientific terms with a relation, modeled toward subject-predicate-object RDF statements for KG building. The task is to automatically extract these elements given a new NLP article. Have a look at our pilot annotation task description paper published in the 1st Workshop on Extraction and Evaluation of Knowledge Entities from Scientific Documents co-located with the ACM/IEEE Joint Conference on Digital Libraries (JCDL 2020).
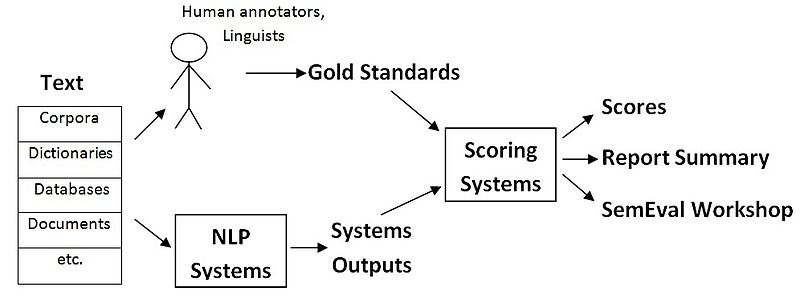
NCG is organized under the umbrella of the well-known Semantic Evaluation (SemEval) series that has been running since 1998. SemEval tasks bring together researchers with similar text mining and machine learning interests, and facilitate the collaborative building of computational semantic analysis systems. As depicted in Figure 1, our task will conform to the standard SemEval framework for tasks where the gold standards will be released by the organizers and the NLP systems will be developed by the task participants.
In the context of the ORKG digital library, we ask certain broad questions such as: What if scholarly knowledge communicated in the scholarly literature would be FAIR, also for machines? What if the global scholarly knowledge base would be more than a repository of digital documents? How would this change the global access to as well as the reuse of scholarly knowledge?
NLPContributionGraph seeks to concretely find the answers. We invite the scholarly communication, information science and related research communities to contribute to the vision and the ORKG, specifically, and help to shape the future of scholarly communication. You may find detailed participation information and the task timeline here.