Behind the Scenes of a DFG Research Project — Making Five Million Scientific Open Access Images Available and Collaborating with the Wikimedia Community
Scientific articles have been a rarely exploited source for finding images that can be used elsewhere. The NOA project wants to change that. So far, several million images from freely available scientific articles have been collected and been described with text data mining methods, so that they are findable in a search engine. But how do they get to Wikimedia Commons to make them available for many people in the long run? Do all the images belong there at all? In this article, that was originally published in German on the Wikimedia Deutschland blog, Lucia Sohmen, Ina Blümel, and Lambert Heller from the Open Science Lab at TIB describe their reflections on the questions and how they solve the challenges.
What is NOA?
NOA is short for „Nachnutzung von Open-Access-Abbildungen“ („Re-use of Open Access images“), a project funded by the DFG since 2017. The proposal was made available here even before review in the style of our Open Science culture. The Open Science Lab at the German National Library of Science and Technology (TIB) is a project partner alongside Hannover University of Applied Sciences and Arts, and Wikimedia as a supporter of the project proposal. A short introduction to NOA has already been published here. Early in the process, we started discussing the project and the interim results with the Wikimedia community, e.g., at Wikicite 2016 and Wikicite 2018. Last week we presented the new NOA functions and the cooperation with the community at the Bibliothekartag.
NOA aims to make images from scientific Open Access articles accessible for subsequent use in a sustainable way. To achieve this, articles from various publishers are downloaded on a large scale. Most of these articles are in English. All of them, of course, with a Creative Commons license, mostly CC-BY. This allows the content to be freely distributed and modified as long as the original author is named and changes are marked. Therefore this license is also compatible with Wikimedia Commons.The links to the images and the image captions are extracted. In addition, all relevant metadata of the articles are extracted — for example authors, titles, or journal names.
The images are described by using automated methods. For this purpose, categories from Wikipedia and Wikimedia Commons have to be assigned to each image. The image captions and the context in which the image is mentioned in the article are already known. The relevant terms are extracted from these paragraphs. Then we search the English Wikipedia these terms and look for the articles in which the terms occur most frequently. Rarer terms are weighted higher. If a rather frequent word such as „year“ is used in a caption, this does not automatically mean that an article in which the word often appears is relevant for the image. For less common words like „glycosaminoglycans“, it is much more likely that an article with this word will deal with the same subject as the image. If there are many such articles in a Wikipedia category, that category is used to describe the image. If you are interested in this method in more detail, you can read about it here. The Wikidata API can be used to determine which Wikidata item belongs to this category and which category from Wikimedia Commons matches it.
This means we keep information in three(!) classifications for each image. One of the reasons for this is that Wikimedia Commons is currently restructuring: In the future, the categories on commons could be replaced by multilingual structured descriptions, which is currently being tested in the Structured Data project. In order to fit into the new data format, our indexing would also have to adapt. Since Structured Commons is mainly about describing what is depicted on an image with the help of Wikidata, our automatic indexing might reach its limits. Scientific images often depict information instead of clearly defined visual entities, making it difficult for people to formulate which concept is depicted, so teaching this to machine is even harder. We have already given feedback on the discussion pages so that images like ours can be effectively described in the future. A more intensive exchange of Structured Commons and NOA would be a good idea. We are ready for this 🙂
The images can be found via a search engine. In general, we are not fans of silos that are not linked to other data sources and force users to constantly learn new platforms. Nevertheless, we decided to develop our own search engine, as it is a long process until the images are available on Wikimedia Commons and they should be accessible to everyone before.
A search result looks like this:
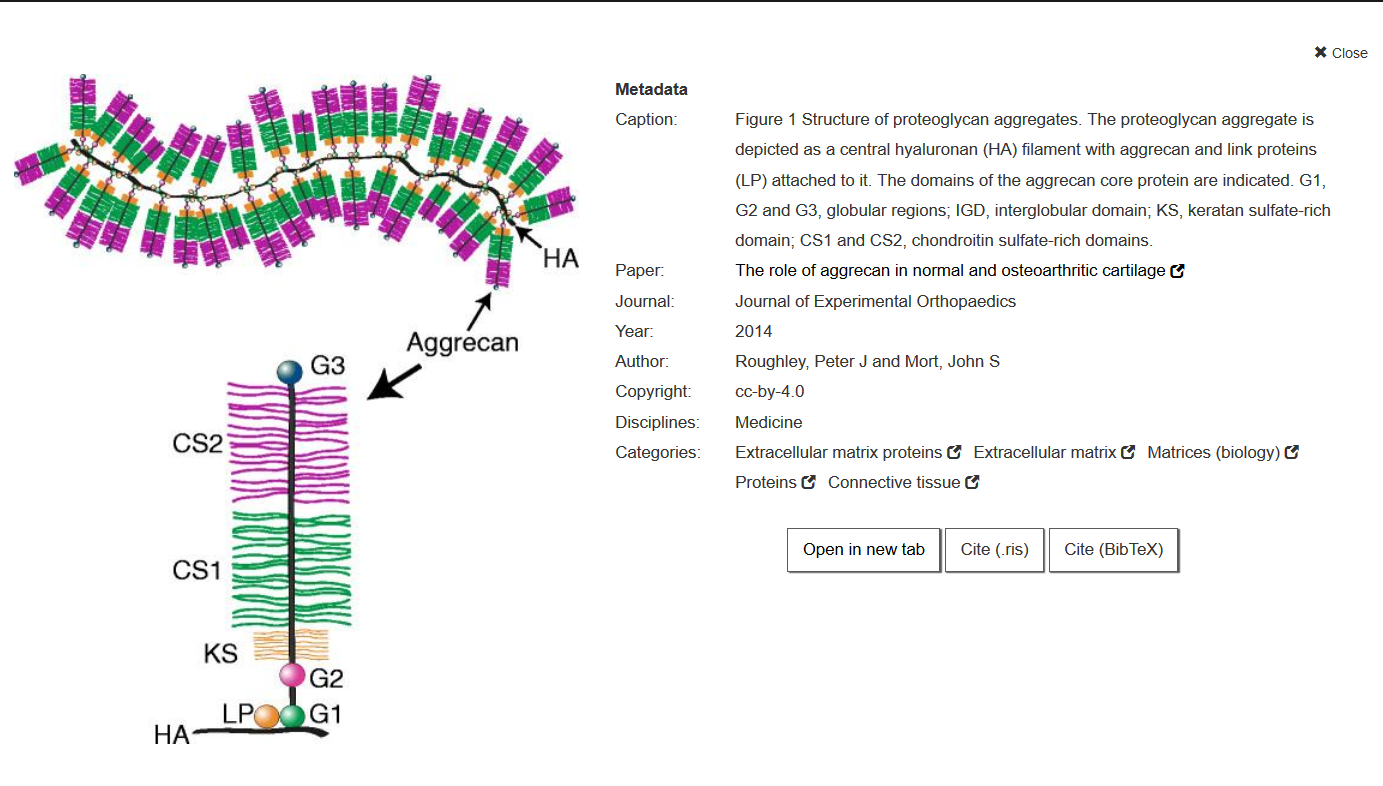
Why aren’t all images uploaded at once?
There is a large amount of images with descriptive metadata. There are also several tools for uploading large amounts of images to Wikimedia Commons, such as Pattypan and the GLAMwiki Toolset. Technically it is possible to upload all images now. So what kept us from doing that?
By exchanging ideas with volunteers from previous similar projects, we knew that the community is very concerned about quality in mass uploads and that these should not be started without prior consultation. In addition, only some of the images are suitable for subsequent use for a few reasons:
A first challenge is copyright. While most images have formal licenses such as CC-BY-4.0, there are some that only describe the rights in text form or use a license that is not suitable for uploading to Commons. After such images have been filtered out, we are left with a completely different problem: Some authors use images that are not under a free license, for example from commercial image databases. Others quote images from publications by other authors. The latter can — but don’t have to — be under a free license. However, even then the metadata is no longer correct, since the source of the image is a completely different article than the one from which it was extracted. These problem cases can be filtered out by an algorithm, but it obviously does not have a precision of a hundred percent.
The second challenge is the relevance and comprehensibility of the images. Many are only understandable in the context of the article and / or not relevant outside of it. Some examples are images showing maps with investigated locations, or images showing a graph with the caption „Results from the experiment“ without further information. Others have low resolutions or show only text. Apart from such obvious problems, there are also many images whose relevance is difficult to estimate. Project team members without expertise in the domain often cannot grasp what exactly is shown in an image, let alone assess whether the content might be useful for others.


- Image with low resolution. Zhao, Xiaolei et al. „Application of Spontaneous Photon Emission in the Growth Ages and Varieties Screening of Fresh Chinese Herbal Medicines“, Evidence-Based Complementary and Alternative Medicine doi:10.1155/2017/2058120, CC-BY-4.0
- Image with text. Brodić, Darko and Milivojević, Zoran N. and Maluckov, Čedomir A. „Recognition of the Script in Serbian Documents Using Frequency Occurrence and Co-Occurrence Analysis“, The Scientific World Journal doi:10.1155/2013/896328, CC-BY-4.0
How do others solve the problems?
NOA is not the first project to deal with mass uploads to Wikimedia Commons. Other projects have also uploaded media from Open Access articles:
For several years, the Open Access Media Importer Bot crawled all articles from PubMedCentral (database for Open Access publications in the life sciences) and imported audio and video files into Wikimedia Commons. It uploaded everything without further selection. Since such media formats are rare in articles, however, they uploaded just under 40,000 files.
As part of the “Signalling OA-ness” project, the Recitation Bot uploaded media from Open Access articles quoted on Wikipedia. The selection is therefore made on the basis of whether articles have already been relevant to Wikimedia projects in other contexts. This is an elegant way to determine whether material is important for users.
We also had our own ideas on how to select the right images. One could try to train a machine learning algorithm based on the image descriptions or perhaps even the image content that filters out the relevant images. Or we could search the areas on Wikipedia where many articles have no pictures. A similar tool already exists for Wikidata items that do not have a corresponding image.
Our solution
There might be even more possibilities assess the relevance for Wikimedia Commons. So far, however, there is one main reason why images end up there: Someone thinks that an image should be on Commons and uploads it.
This criterion should also be applied to NOA images. Users of Wikimedia Commons should be able to decide for themselves which of the images should be uploaded. To make this as easy as possible, we have developed two different upload options. We were inspired by two other tools that also upload images from another service to Wikimedia Commons. FlickrFree, which displays newly uploaded, freely licensed images from Flickr and allows you to upload with a single click, and Flickr2Commons, which allows you to easily upload images found on Flickr. Our two solutions are similar, but differ in that they are integrated into the search engine.
1. Upload after a search
If you search for a picture in the search engine, a button with the inscription „Upload to Wikimedia“ is displayed below the individual results. After clicking it, you will be asked to log in with your Wikimedia account and allow NOA to upload images. Once this has been done, you can select the appropriate categories and upload the image with all data to Wikimedia Commons by clicking on „Upload“. The result appears as a link and you can view it directly and edit it if necessary.
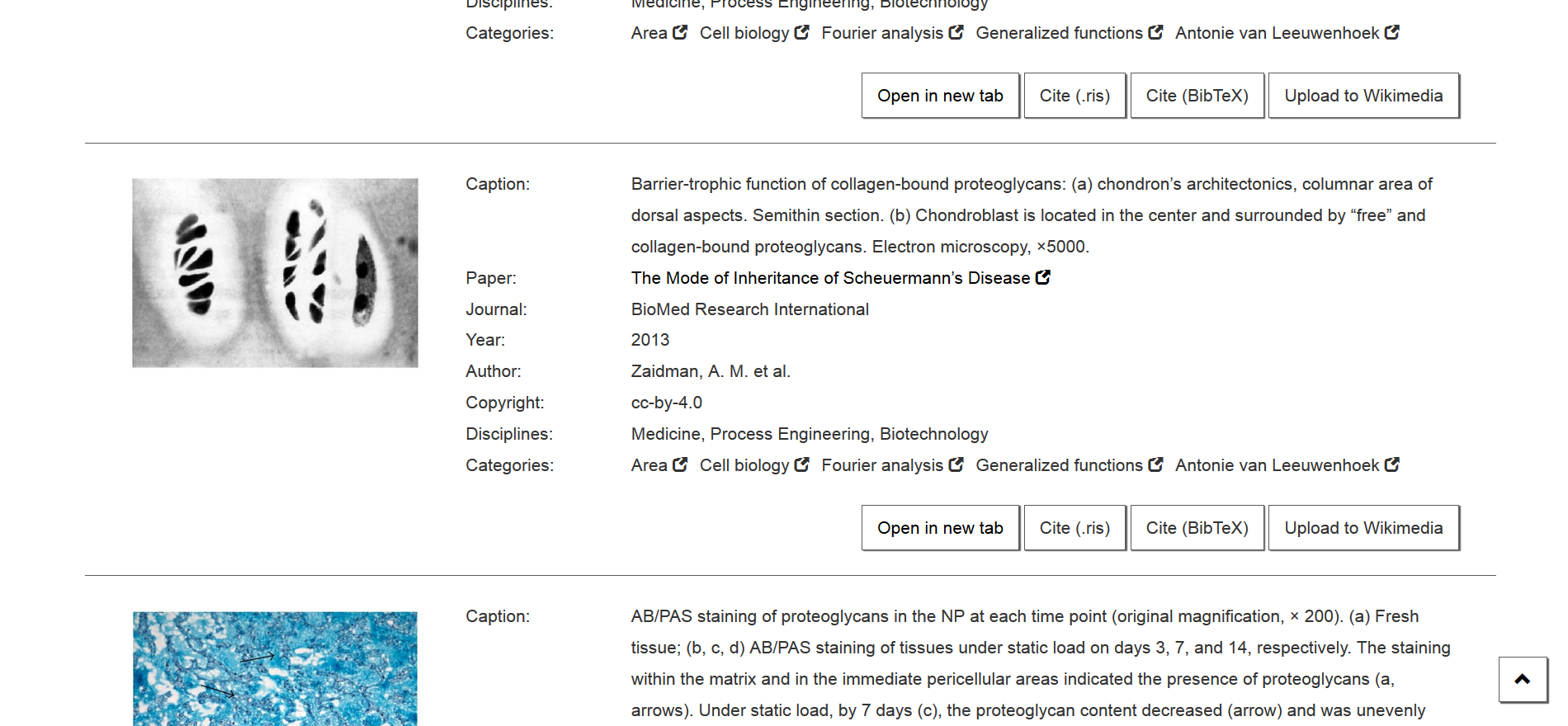
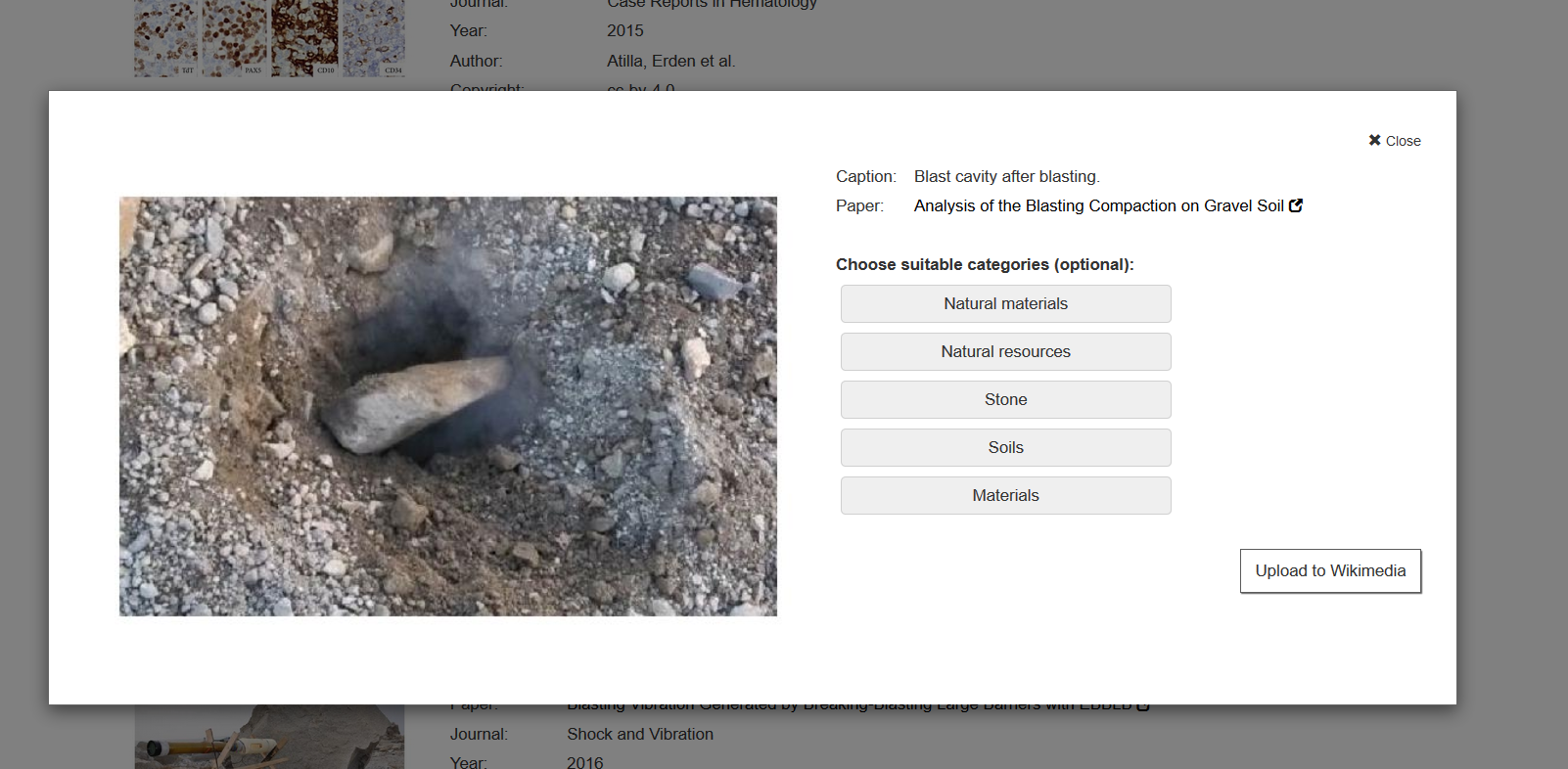
Watch the how-to of the upload function:
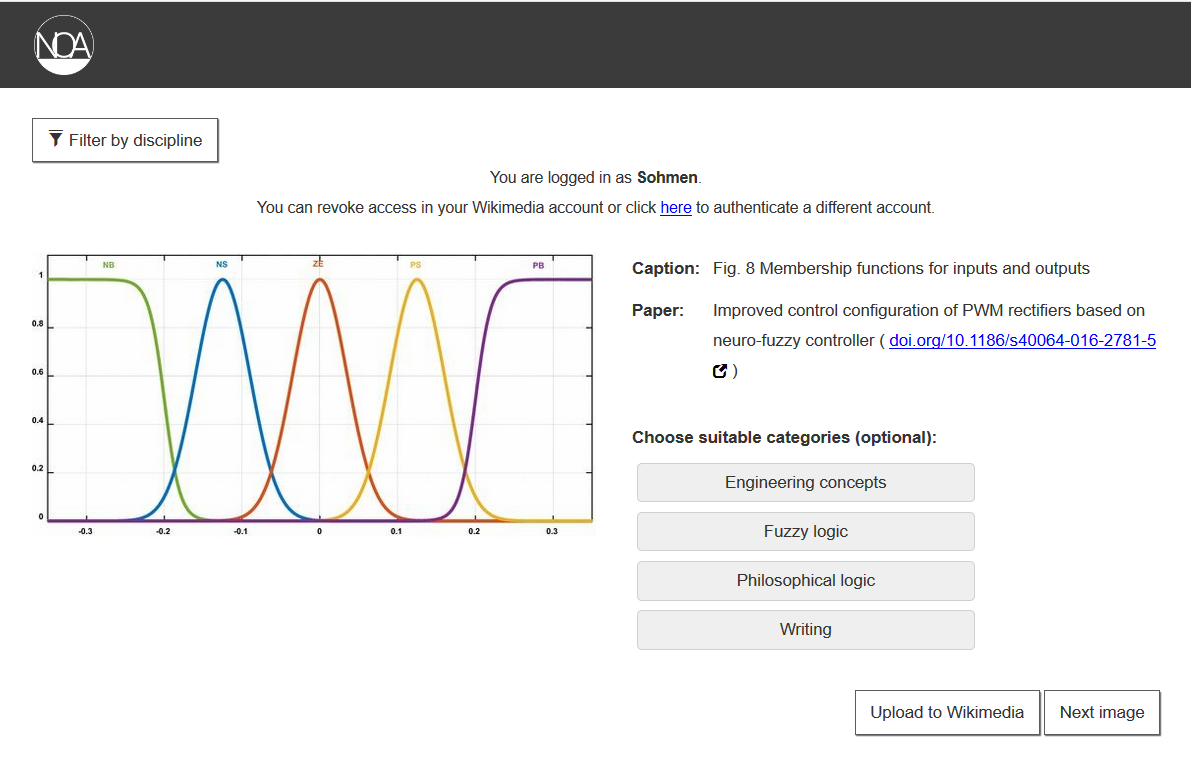
2. The Random Upload Tool
If you don’t have a specific topic in mind, but still want to contribute to transferring images from the project to Wikimedia Commons, you can use the Random Upload Tool. It shows randomly selected images and you can decide if the image should be uploaded or if a new image should be displayed. If an image is not uploaded, it will not be displayed to other users. It is possible to select suitable categories for a picture in this format as well. The images can be filtered by subject area. Medicine is filtered out by default because there are a lot of images that many people may not want to see. However, the subject can be selected in the subject filter. The tool can be tested here.
In the future
In the future we want to develop further possibilities to find relevant images. One idea would be to find Wikipedia articles without images and automatically suggest suitable images. A similar tool already exists for Wikidata. It is also conceivable to support authors directly in creating articles and to suggest relevant images based on the newly written text. Perhaps an algorithm can be trained to learn from the uploaded images and independently decide which images are suitable. They can then either be uploaded automatically, or suggested to users for upload.
In order to increase the number of relevant images, new sources should also be found. So far the collection in NOA is biased towards engineering and life sciences. The humanities and social sciences are less represented. If these are included, the project can create added value for completely new user groups.
Participate
The more people participate, the more images can be made available to everyone through Wikimedia Commons. Whether someone finds a nice picture through the search or the Random Upload Tool — uploading is easy. All you have to do is allow this feature in your Wikimedia account (which can undo at any time). Any contribution is welcome.
Feedback is also a great help for us: How do you see the project in general? How is the quality of the images? What is completely missing so far? Which other functions could be added?
We are looking forward to your feedback, comments and general opinions!
Eine Antwort auf “Behind the Scenes of a DFG Research Project — Making Five Million Scientific Open Access Images Available and Collaborating with the Wikimedia Community”