Geolokalisierung von Fotos mithilfe künstlicher neuronaler Netze
Die erfolgreiche Schätzung des Aufnahmeorts eines Fotos ermöglicht eine Reihe interessanter Anwendungen. Ein solcher Geo-Schätzer kann beispielsweise zur Durchsuchbarkeit von historischen Bild- und Videoarchiven (anhand des Aufnahmeorts) beitragen oder auch zur Identifizierung von Widersprüchen in Nachrichten „Fake News“ (Nachrichtenmeldung zu einem Ort zeigt in Wirklichkeit einen anderen Ort) unterstützend beitragen.
Wir haben einen auf künstlicher Intelligenz (KI) beruhenden (Geo-)Lokalisierer entwickelt, der ausschließlich mittels des Bildinhaltes eine Schätzung abgibt, wo auf der Erde ein Foto aufgenommen wurde. Genauer gesagt basiert unser Ansatz auf tiefen neuronalen Netzen (deep convolutional neural networks), die dem Bereich des maschinellen Lernens zuzuordnen sind, was wiederum ein Teilgebiet der KI ist. Solche neuronalen Netze modellieren mit Methoden der Mathematik die menschliche Informationsverarbeitung im Gehirn, insbesondere die Verknüpfung von Nervenzellen (Neuronen). So hat auch unsere Ortsbestimmung das menschliche Nervensystem zum Vorbild und wird durch tiefe neuronale Netze realisiert.
Das neuronale Netz wird mit mehreren Millionen Beispielbildern trainiert, welche anhand ihrer GPS-Koordinaten geographischen Zellen auf der Erdoberfläche zugeteilt wurden. Das System lernt mittels dieser Aufteilung spezifische Bildmerkmale, die im optimalen Fall für eine Geo-Zelle eindeutig sind und trainiert (seine Fähigkeit) zwischen diesen zu unterscheiden.
Aufgrund unterschiedlich häufig fotografierter Orte verteilen sich die Trainingsbilder ungleichmäßig über die Erde. Um diesem Problem entgegenzuwirken, wird die Erde, wie auf der folgenden Abbildung gezeigt, in Zellen unterschiedlicher örtlicher Auflösung unterteilt. Je mehr Bilder für eine Region vorhanden sind, desto feinere Zellen sind in dieser Region vorhanden. Auf diese Weise lernt das Netz in „beliebteren“ Gebieten, differenziertere Geo-Schätzungen zu machen.
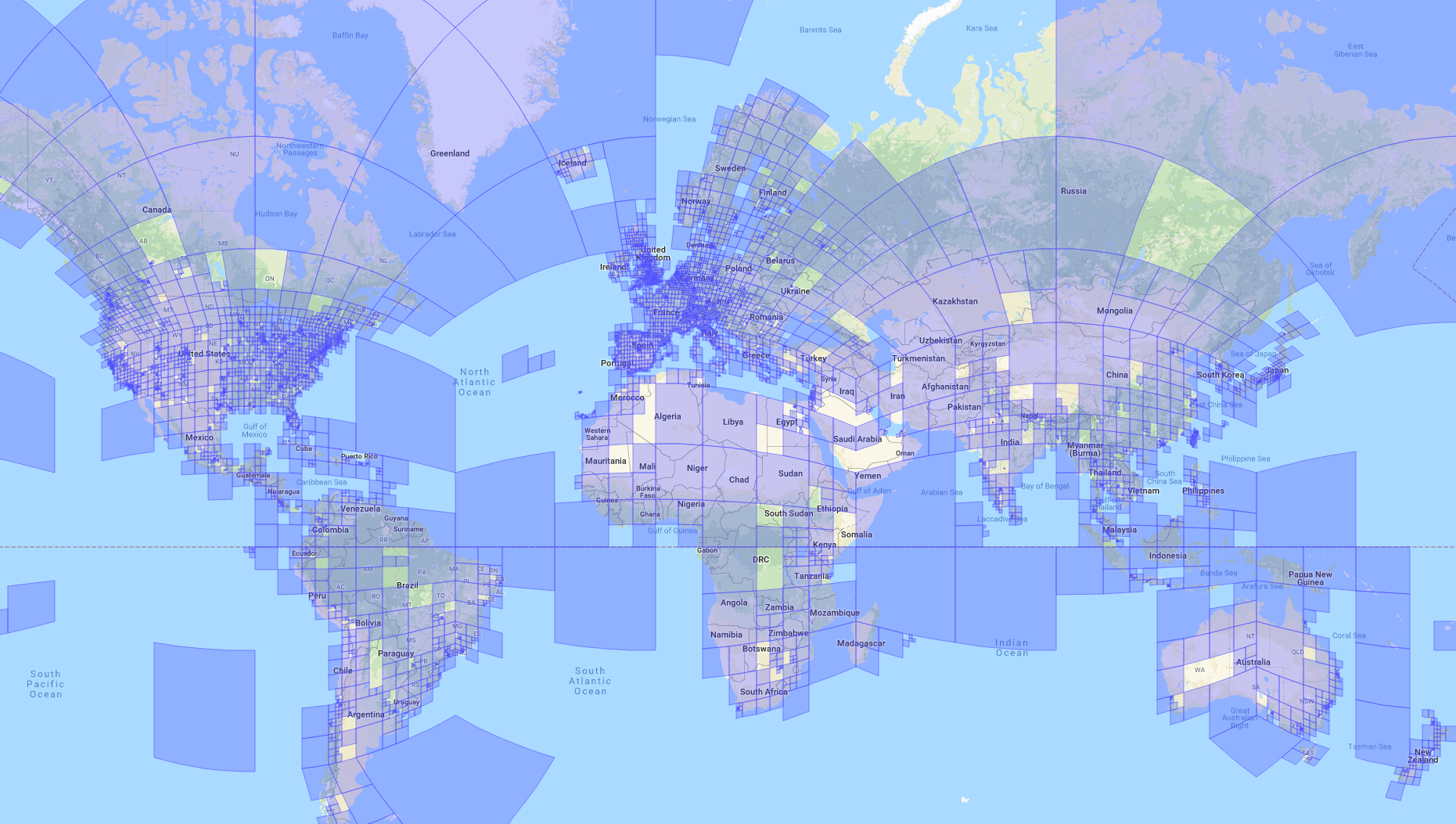
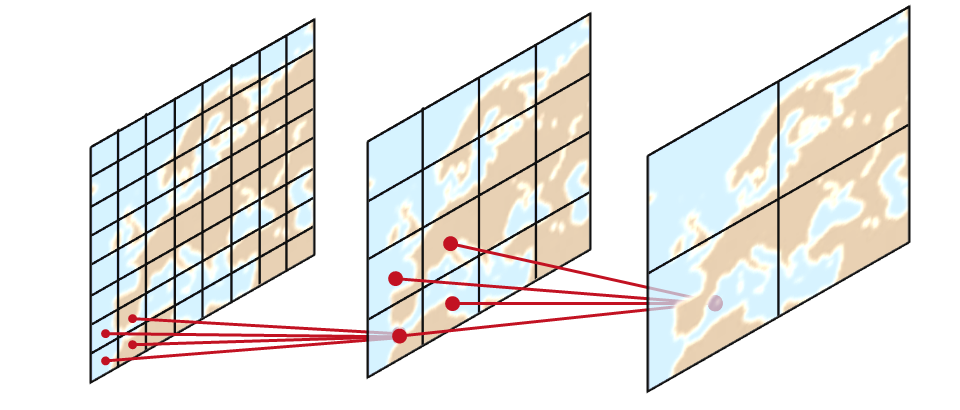
Die bislang beschriebene Idee stammt ursprünglich vom PlaNet-Ansatz¹, der von Google-Forschern vorgeschlagen und mit ca. 91 Mio. Bildern trainiert wurde. Durch die Einbeziehung von Kontextinformationen gelang es uns, diesen Ansatz zu verbessern. Hierbei haben wir hierarchisches Wissen für unterschiedliche feine bzw. grobe Zellenaufteilungen der Erde in den Lernprozess des Gesamtsystems integriert. Wahrscheinlichkeiten für Zellen der feinsten Aufteilung werden bei dieser Idee durch die der gröberen Aufteilungen verfeinert. Dieses Vorgehen basiert auf der Tatsache, dass jeweils eindeutige Verbindungen zu Elternzellen der übergeordneten Aufteilung bestehen.
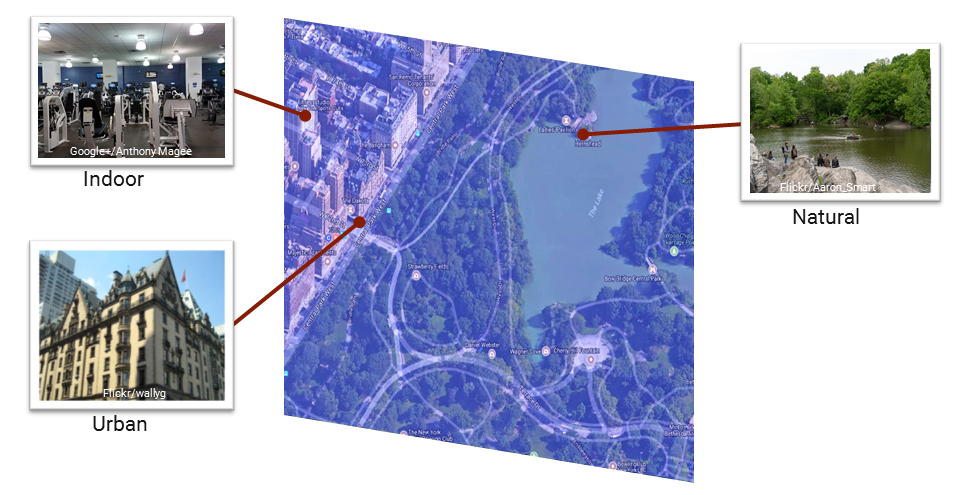
Zellen können aus sehr unterschiedlichen Bildern bestehen, für die das Modell eine gemeinsame Repräsentation lernen muss. So kann zum Beispiel eine Zelle am Central Park in New York neben Innenaufnahmen auch Stadt- und Naturaufnahmen beinhalten. Stadtbilder zeichnen sich hauptsächlich durch Architektur, Menschen und spezifische Objekte wie Autos oder Straßenschilder aus. Natur- oder Innenaufnahmen hingegen werden durch die Flora und Fauna oder Inneneinrichtungen definiert. Um die Diversität in den Zellen zu reduzieren, verwenden wir separat trainierte Netzwerke für die drei genannten Umgebungs- bzw. Szenentypen. Auf diese Weise kann ein entsprechendes Modell spezifischere Merkmale für einen Szenentyp extrahieren, welche die Verortung des Bildes erleichtern können.
Unseren Ansatz haben wir auf der European Conference on Computer Vision (ECCV) 2018 in München veröffentlicht² (Open-Access-Version hier). Die ECCV ist eine der hochrangigsten Konferenzen im Bereich des künstlichen, maschinellen Sehens (Computer Vision) und hat eine durchschnittlich Annahmequote von weniger als 30%. Auf derselben Konferenz wurde zeitgleich auch CPlaNet³ vorgestellt, eine Weiterentwicklung des PlaNet-Verfahrens von Google, welche mit kombinatorischen und sich lokal überlagernden Geo-Sektoren arbeitet. Auf den für das Geo-Problem etablierten Benchmark-Datensätzen konnten wir mit unserem Verfahren und einem Bruchteil der Trainingsbildermenge (4,7 Mio. gegenüber 30,3 Mio.) die derzeit besten Ergebnisse präsentieren.
Dennoch ist das allgemeine Geolokalisierungsproblem damit noch (lange) nicht gelöst. So schätzt unser Verfahren auf dem kleineren der beiden Benchmarks bei etwa 80% der Bilder den korrekten Kontinent, bei noch 43% der Bilder die korrekte Stadt. Eine auf einen Kilometer genaue Schätzung der Straße kann nur noch bei etwa 17% der Bilder ermittelt werden. Ein Grund hierfür ist, dass der Geo-Schätzer während des Trainings selten oder gar nicht „gesehene“ Orte, nicht zuordnen kann, so wie es intuitiv auch beim Menschen der Fall wäre. So fassen größere Zellen zum Beispiel selten fotografierte geografische Sektoren in Größenordnungen von bis zu 4,000 km² zusammen. In diesen Fällen verursacht auch die durch den Zellenschwerpunkt der Bilder ermittelte GPS-Position schwerwiegendere Fehler. Zukünftig könnte das Verfahren daher durch Fotos bislang weniger abgedeckter Orte verfeinert werden. Auch ein weiterer Regressor, welcher die GPS des statischen Zellenschwerpunkt durch eine weitere Schätzung innerhalb der Zelle ersetzt, könnte eine Verbesserung bringen.
Nachfolgende Abbildungen zeigen eine Aufnahme des Hauptbahnhofs Hannover von 1975 (Bild-Quelle: Hannoversche Allgemeine Zeitung) und die geschätzte GPS-Position unserer browserbasierten Demo.


Unser Modell ordnet das historische Bild korrekt Hannover zu. Die GPS-Schätzung liegt sogar relativ konkret zwischen dem Hauptbahnhof und Kröpcke. Neben der final geschätzten Position auf der Weltkarte, zeigt das Tool auch weitere mögliche Positionen, die das Netz aufgrund geringerer Wahrscheinlichkeiten nicht berücksichtigt. Der zweite Tipp des Netzes ist in diesem Zusammenhang das über 350 Kilometer entfernte Dresden.
Derzeit arbeiten wir auch an der Erklärbarkeit der Schätzungen unseres Netzes. Dazu nutzen wir Aktivierungskarten, sogenannte Class Activation Maps. Diese weisen, wie auf der nächsten Abbildung gezeigt, auf Bildregionen hin, die stärker zur Entscheidung über die Zellenklassifikation beitragen.

Unter https://labs.tib.eu/geoestimation kann bereits eine Betaversion mit dieser Funktion getestet werden.
Im Rahmen des von der Deutschen Forschungsgemeinschaft (DFG) geförderten Projekts VIVA (Visuelle Informationssuche in Videoarchiven) arbeiten wir auch an einer automatisierten Verortung von historischem Videomaterial der DDR.
Wer außerdem Interesse an den Netzwerk-Modellen hat, findet diese und weitere Informationen zu unserer Arbeit in folgendem Repository: https://github.com/TIBHannover/GeoEstimation.
Geolokalisierungstool auf der MS Wissenschaft
Unter dem Motto „Woher stammt das Bild?“ ist die TIB im Wissenschaftstjahr 2019 zum Thema Künstliche Intelligenz mit dem in der Forschungsgruppe Visual Analytics entwickeltem Geolokalisierungstool auf der MS Wissenschaft vertreten.
Beitrag im c’t-Magazin
Unter dem Titel „Wo war das noch mal?“ stellt Redakteur Arne Grävemeyer das Geolokalisierungstool in der Ausgabe 5/2019 der Zeitschrift c’t vor.
Fußnoten:
¹ Weyand, T., Kostrikov, I., Philbin, J.: Planet – photo geolocation with convolutional neural networks. In: European Conference on Computer Vision. pp.37–55. Springer (2016)
² E. Müller-Budack, K. Pustu-Iren, R. Ewerth: Geolocation Estimation of Photos using a Hierarchical Model and Scene Classification. In: European Conference on Computer Vision. pp.575-592. Springer (2018)
³ Seo, P.H., Weyand, T., Sim, J., Han, B.: Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. In: European Conference on Computer Vision. pp.544-560. Springer (2018)