Konkrete Ratschläge für bessere Metadaten in wissenschaftlichen Softwareprojekten
Im ersten Blogpost zu diesem Thema wurde zur Auffindbarkeit wissenschaftlicher Software anhand von PIDs beraten. Hier folgt die Übertragung des nächsten Teilaspekts der FAIR-Prinzipien von Forschungsdaten (Kraft 2017) auf wissenschaftliche Software.
F2. Software wird mit umfangreichen Metadaten beschrieben
Jede Software sollte mit ausführlichen (siehe R1) Metadaten beschrieben werden: Diese dokumentieren u.a., wie die Software entstanden ist, wer sie programmiert, verändert oder publiziert hat und unter welchen Bedingungen sie verwendet werden darf. Metadaten liefern somit den notwendigen Kontext für die richtige Anwendung der Forschungssoftware. Je maschinenlesbarer diese Informationen sind desto besser.
Hier beginnen sich die Unterschiede von Daten und Software zu zeigen. Während erstere nach ihrer Erfassung meist statisch bleiben (selbst wenn in einer fortlaufenden Studie neue Datensätze hinzukommen), kann Software sich weit dynamischer weiterentwickeln, da ein breiteres Spektrum an Kontributionen möglich ist (Architekturentscheidungen, Programmcode, Tests, Grafikdesign, Dokumentation, Anleitungen, Übersetzungen, etc.). Somit kann beinahe jeder Mensch zu einem Softwareprojekt etwas beitragen, und der Softwarenachhaltigkeit steht eigentlich nur die Qual der Wahl nützlicher Werkzeuge im Wege. Es gibt viele, was Fluch und Segen zugleich sein kann, aber diese sind sowohl einzeln, als auch in Kombination jeweils nützlich.
- Während der Programmierarbeit anfallende Urheberinformationen über eine Software sollten mittels eines Versionskontrollsystems erfasst werden. Neben Autor*in und Zeitstempel sind insbesondere erklärende, zusammenfassende und begründende Kommentare („commit messages“) essentiell wichtig für die Nachvollziehbarkeit der Änderungen zwischen den Versionen. Diese Art der Metadatenanreicherung kann man zudem als Teil der Code-Dokumentation verstehen, die sowohl dem eigenen, zukünftigen Ich nützt, als auch Kolleg*inn*en, Gutachter*inne*n, usw.
- Im F1-Blogpost wurde als Versionskontrollsystem Git empfohlen, wobei es auch weitere gibt. Relativ niederschwellig gelingt der Git-Einstieg mit GitHub Desktop (offizielles 30min-Webinar & Anleitungen), aber auch andere grafische Oberflächen sind verfügbar. Die Git-Plattformen GitLab und GitHub bieten ebenfalls Anleitungen an. Wer sich mittels Kommandozeile in Git einarbeiten möchte, sollte die Software-Carpentry-Lesson “Git Novice” probieren.
- Wird der versionskontrollierte Softwarequellcode auf eine Hosting-Plattform hochgeladen (öffentlich oder privat), bieten diese oft rudimentäre Metadaten-Felder zum Ausfüllen an (Beschreibung, Webseitenlink, Schlagwörter, etc.). Derartige Angebote sollten genutzt werden, ebenso wie Vorlagen, Ausfüllhilfen, usw. für
README,LICENSE, o.ä. Dateien.
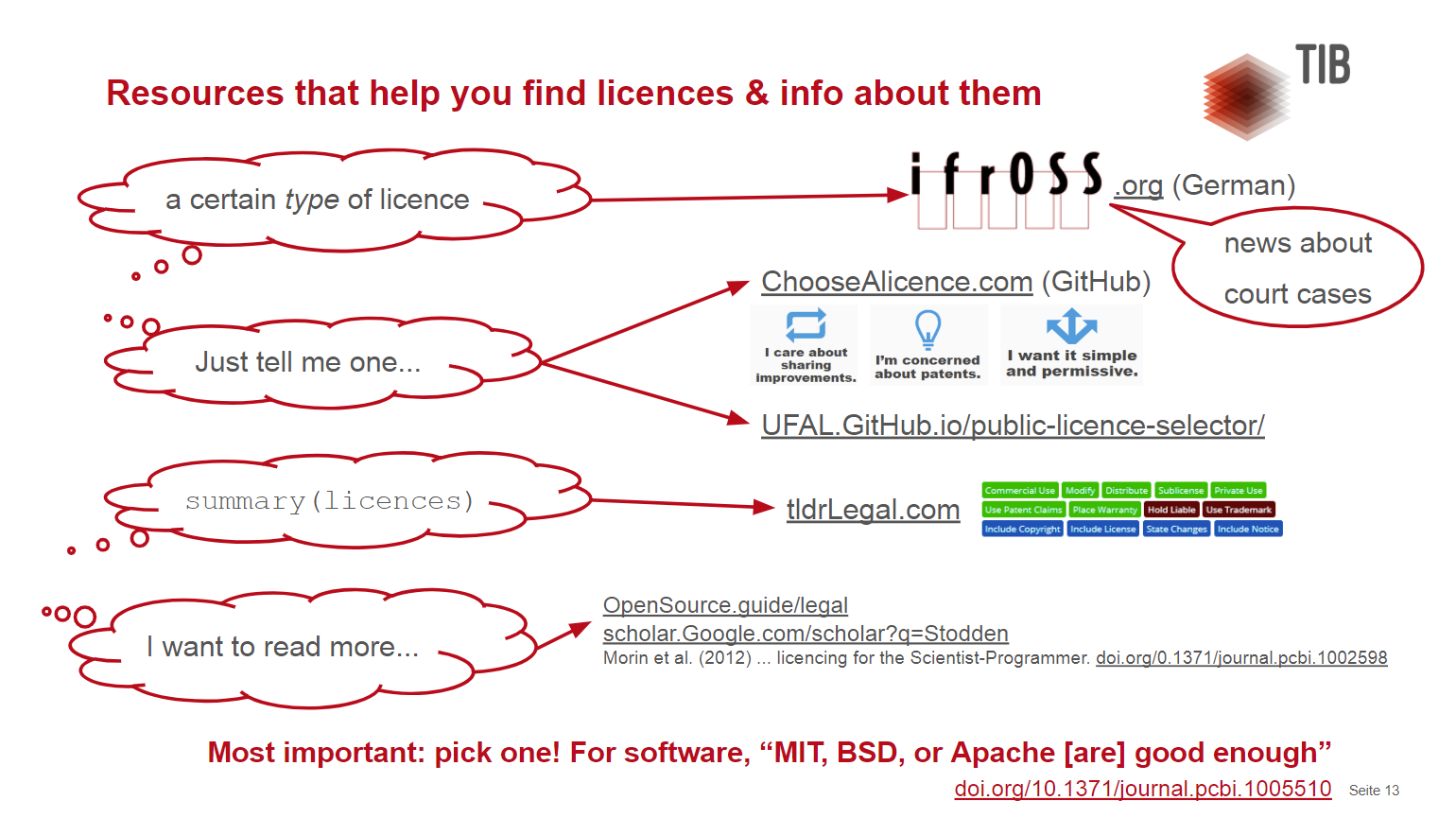
- Ein sehr wichtiges Metadatum ist gerade im deutschen Urheberrecht (Forgó 2017) die Lizenz, um Nachnutzung und Weiterentwicklung zu gewährleisten. Selbstverständlich sollte im Open-Science-Geist eine möglichst freie Lizenz gewählt, und auch von den Institutionen unterstützt, werden. Bspw. eine, die die Open Source Definition erfüllt. Als deutsches Äquivalent sei das Lizenz-Center des Instituts für Rechtsfragen der Freien und Open Source Software empfohlen. Fall-basierte Entscheidungshilfen und Zusammenfassungen finden Sie auf tldrLegal.com und ChooseALicense.com. Eine ausführliche Erläuterung von Lizenzen für wissenschaftliche Software finden Sie auch in unserem AV-Portal (Hammitzsch 2018).
- Soweit es im jeweiligen Fachgebiet in der Werkzeugkiste des Softwareprojektes Konventionen für Metadatenformate oder -dateien gibt, sollten diese erstellt und genutzt werden. Für die Programmiersprache R bspw. gibt es die Konvention, Pakete zu erstellen, und sie mittels
DESCRIPTION-Dateien zu beschreiben. In Kombination mit der im vorherigen Blog-Post erklärten “Zenodo-ver-DOI-ung” entstehen so publizier- und zitierbare wissenschaftliche Artefakte.
- Zur maschinenlesbaren Annotation von Softwarearchiven können Terme aus etablierten Vokabularen verwendet werden, suche z.B.
Softwareauflov.LinkedData.es.
- Auch die nicht-Code-Anteile eines Projektes können als Metadaten verstanden werden, denn Dokumentation, Änderungsprotokoll usw. etablieren Kontext, Qualität, Zustand oder Merkmale eines Softwareprojektes. Da diese mittels der in F1 > Rolle der Wissenschaftler > 2. empfohlenen Zenodo-Anbindung ebenfalls ver-DOI-t und gesichert werden, ist es ratsam, Doku, Änderungsprotokoll usw. ebenfalls als Dateien im Git-Repository unter Versionskontrolle zu legen. Zusätzliche Nützlichkeit erfährt diese Strategie durch die immer weiter fortschreitenden Webseite-Generatoren, die die populären Git-Plattformen (Stichwort: Pages), sowie Helfertools wie das R-Paket pkgdown, anbieten. Kurz gesagt: je mehr Projektteile und -arbeit im Git-Repository eines Softwareprojektes erfolgt, desto automatischere Nutzungsmöglichkeiten bieten sich für die Ergebnisse der menschlichen Arbeit.
Dieses Prinzip (“notwendige menschliche Arbeit in ‘Plain Text’-Formate zu fokussieren, sodass Arbeitsergebnisse gut automatisiert nachnutzbar werden”) kann als Brückenschlag zum machine-actionable-Fokus der FAIR-Prinzipien (Wilkinson et al. 2016) verstanden werden.
Literaturverzeichnis
Forgó, Nikolaus, dir. 2017. Legal Requirements for Software Sharing and Collaboration. Technische Informationsbibliothek. https://doi.org/10.5446/31029.
Hammitzsch, Martin. 2018. “Reusability: Software Licensing.” Technische Informationsbibliothek (TIB). https://doi.org/10.5446/37829.
Kraft, Angelina. 2017. “Die FAIR Data Prinzipien Für Forschungsdaten.” TIB-Blog. September 12, 2017. /2017/09/12/die-fair-data-prinzipien-fuer-forschungsdaten/.
Wilkinson, Mark D., Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, et al. 2016. “The FAIR Guiding Principles for Scientific Data Management and Stewardship.” Scientific Data 3 (March). https://doi.org/10.1038/sdata.2016.18.